Chapter 1
Problem Statement and Goals
In the workplace many work orders are handwritten on paper rather than recorded in a digital format. These papers, while archived, are never referenced or used.
Within many organizations, handwritten work orders consisting of tacit and explicit knowledge are created throughout the course of normal business by work crews. This knowledge, if properly captured and utilized may contain beneficial knowledge in the field of its origin and for future reference for others. As Asgari et al. (2005) describe in an evaluative study, while literature and documentation are used as resources for information within a company, tacit knowledge often is overlooked. Experience and interaction between employees and their tasks is theorized to be crucial to the overall well being of the company. Asgari et al. confirm that when tacit knowledge is gathered and proved to be beneficial in an organization, the source from which the knowledge comes is of sufficient value and worth extracting.
When knowledge is explicitly desired, it is often collected using formal methods requiring direct input from participants (John, Ian, & Andres, 2001; Liu & Fidel, 2007). These procedures form an easily maintainable digital format and are indexed into a larger system for convenient access. While these methods and formats are ideal for organization and utilization, the capture process may be limited to those willing and/or mandated to participate as well as limitations imposed by time constraints (Cao & Compton, 2005; Chklovski, 2005). Attempts may be made to ensure that the processes are accessible and intuitive, but may still receive resistance by those who are required to participate (Chklovski, 2005; Marks, Polak, McCoy, & Galletta, 2008). If the process is inconvenient, support may lessen and the potential for gathering valuable knowledge will in turn lessen. In cases where data gathering is forced, employees may only record that which is minimally needed to satisfy the output requirement (Bossen & Dalsgaard, 2005). Additionally employees may resist sharing their knowledge in order to retain job security (Marks, et al., 2008). In cases where knowledge extraction is not specifically required, employees may still produce records in the form of handwritten notations such as work orders. While less formal, this method is convenient for those lacking the time or resources to digitally capture their knowledge. In some cases this procedure becomes standard business practice when no alternative exists (Govindaraju, 2005; 2007).
Work orders in this context were handwritten documents created by employees while in the field (Howe, Rath, & Manmatha, 2005). These documents are not directed towards contributing to a knowledge base nor is there an attempt to process the information beyond completion of the task (Howe, et al., 2005; Kaiser, 2005; Kienzle & Chellapilla, 2006). Despite the informal nature of work orders, they are still archived due to the perception that they contain value. However these values are never pursued nor are the work orders referenced at a later point despite this perception of value (Bondarenko & Janssen, 2005). As Asgari (2005) describe, knowledge that is not formally documented is neglected due to time and effort constraints. Employees may recognize the abundance of data, but still lack the resources or motivation to utilize it. This study attempted to establish the value within the handwritten notations as a first step towards validating the value of expanding the effort of transcription and analysis.
This study attempted to evaluate the value of handwritten data within work orders as determined by experts working in the related field. The research built on work performed with verbal knowledge and was tested using a technique suitable for forming a consensus from an expert group. (Goldman et al., 2008; Linstone & Turoff, 2002; Liu & Fidel, 2007)
An evaluative study was used in order to perform the research. In a similar study by Liu and Fidel (2007), the researchers targeted tacit knowledge from technicians in the field. The primary purpose of the study described in this document was to determine the value of expert knowledge and to bridge the gap between senior employees and new hires as well as address the issue of knowledge loss from employees leaving the organization. The environment studied in the research consisted of a city public works service, from which a sample department was chosen to perform the knowledge analysis. During the course of daily work, technicians were sent out into the field with wireless devices programmed to collect data according to predetermined criteria. Common criteria included deviations to standard procedures, historical aspects of job locations, or notes of interest that a technician may find valuable for future visits.
The methodology described by Liu and Fidel proposed an active attempt to collect data from technicians. While this method benefited by advancing and systematically collating the data collected, it was limited to a strict set of pre-determined criteria and did not account for data that may have previously been recorded but not yet referenced. The proposed study built upon Liu and Fidel’s research but targeted work orders, which contain an archive of previously recorded data. The environment was similar and consisted of 20 technicians who perform tasks in the field. These tasks require the completion of a work order consisting of brief informational fields as well as a longer free-form text area. Supervisors oversee the technicians and are called in the event that a situation extends beyond the capabilities of the technician. The supervisors are also content-level experts and are able to assess the importance of the written comments. For this study, the work orders were collected from past projects within a chosen department, and the freeform comments formed the data for the analysis.
Liu and Fidel (2007) analyzed results that fit into pre-determined classifications. For this study, data found within work order comments had to have solid structure and required the consensus of experts. To place value on the handwritten portions of the work orders, the researcher employed a technique that allowed these subject matter experts to assess the importance of each entry. As confirmed by Aggarwal, Yogesh, Pravin and Manimala (2005) in their report on resource estimation, experts have been found to be essential towards assessing subjective value and estimations outside the expertise of the researchers. Goldman et al. (2008) described an implementation of the Delphi Group Technique, which was used to form a consensus among an expert panel. This process eliminated bias or pressure from any one expert and follows a recursive and iterative process resulting in the final determinations. Final consensus was strengthened by using the core recommendations from Linstone and Turoff’s (2002) core applications and techniques. By using Liu and Fidel’s study and Goldman et al.’s process, the researcher attempted to build a repeatable model as well as determined the value of handwritten notations within work orders.
This study attempted to answer questions that would validate the research goals. Answering these questions focused towards confirming the value contained within handwritten documents as well as the importance of expert assessment. After the methodology had been carried out, the study attempted to answer the first research question: How can the value of handwritten data from a specific collection of documents be determined in a manner that is scalable and repeatable? A successful implementation should, if repeated, provide similar results beyond the initial test. Further test cases may vary based on the amount of work orders or the members of the expert panel. While there may be some discrepancies between individual indicators of value for a given repository, the overall process should be considered worthwhile across each implementation. The validity of the process was tested using a quantitative measure of the grand mean for all value indicators, as well as a qualitative analysis using an expert validated survey.
The second research question asked: To what extent is the handwritten information from the collection of documents a valuable source for knowledge acquisition? The ultimate goal for this study is to validate the process from which the information is acquired. Once the data has been extracted and validated by the expert panel, the researcher must determine if the procedure was worth the time and effort to complete based on metrics provided and validated by the expert panel. The answer to this question dictated the continued effort placed upon repeating the process. While the first question attempted to validate if the process can be repeated, the second attempted to validate if it should be repeated.
In environments that rely on knowledge in order to succeed, knowledge gained from any resource is important. Fields such as the educational, medical, and public works communities are some examples where this knowledge is critical and lack of knowledge can result in serious consequences (Cruden, 2006; Govindaraju, 2005). During the course of daily work, employees generate large amounts of information through their experiences and personal knowledge. Someone cannot usually replicate this knowledge without experience in the field, making the employee knowledge base crucial (Asgari, et al., 2005; Bossen & Dalsgaard, 2005). When employees or originators of knowledge do not have the time, motivation, or properly implemented procedures to formally document their experiences or findings, they may resort to paper-based notations, such as work order comment sections in order to devote more time to their primary task.
Handwritten comments result in rudimentary repositories, but provide little use in a situation where documentation is needed quickly or as part of a larger system that shares the knowledge for the benefit of other users (Govindaraju, 2005; 2007; Mooney & Bunescu, 2005). These documents are also usually kept in physical storage mediums; their accessibility is severely limited (Mooney & Bunescu, 2005). They can be scanned into an image data warehouse, but without full text indexing or unique identifiers, their usability decreases (Rath, Manmatha, & Lavrenko, 2004). Until the content of the notations is converted into a format that can be indexed and interpreted, no categorization of the message content is possible (Baglioni, Furletti, & Turini, 2005).
As Goldman et al. (2008) explained in their study about the importance of tacit knowledge, the knowledge produced by experts is extremely important to an organization. While proactive measures can be taken to gather knowledge from employees, there may be situations where employees are no longer present or are unable to adequately convey their knowledge for the benefit of the organization (Asgari, et al., 2005; Makolm, Wei, & Reisinger, 2007). In these cases, it would be worthwhile investigating data repositories that have previously been created (Carenini, Ng, & Zwart, 2005). Documents in existence will remain accessible with proper care and storage and may contain valuable pieces of knowledge that can then be integrated back into the organization. In an effort to target and examine areas where knowledge may have been recorded onto common documents, this study analyzed the content of handwritten work orders (Mooney & Bunescu, 2005).
The primary difficulty with this type of research was the inability to easily digitize and catalogue handwritten data. Unlike Optical Character Recognition and image-based digitization, there is a lack of current technology required to process the handwriting and interpret the data (Bondarenko & Janssen, 2005; Callan, Kantor, & Grossman, 2002). For the purpose of this research project, the technical aspect was bypassed as the literature supported the view that such applications, while developing, are still not in the realm of everyday use (Rath, et al., 2004). Due to the technical limitations, the data was manually extracted throughout the study in order to assess and form conclusions. Since the collection of data was time consuming, the volume of source documents posed a barrier in terms of time commitment on the part of the researcher and the experts. The data extraction process required human transcription of the handwritten text into a spreadsheet, and the manual aspects of this procedure added to this barrier.
Another barrier pertained to the relative value of the data as the value of the data on a given work order varied depending on the person and environment. Some data specifically addressed a job or procedure, while other data was valuable to only someone who had sufficient field experience and was able to determine how a note would apply to future work. Other notes provided critical information from a senior employee that was beneficial for new hires and assisted in creating a tangible record of otherwise tacit knowledge (Liu & Fidel, 2007). The challenge in this case was to utilize the judgment of a panel of experts who possessed the necessary field experience and then formed a single consensus from this group in order to place value on individual work orders. This process required a group technique that systematically filtered the individual conclusions, compared expert opinions and prevented unwanted bias among the panel.
Two null hypotheses were tested to answer the research questions. The first was: There would not be a statistically significant difference in the overall value of work order comments between two repositories from a single department and expert panel as measured by the grand mean across all value indicators designated by the common rubric. This hypotheses validated that the model would be both scalable and repeatable (Ott, 1992).
The second hypothesis was: The overall value contained in work order comments would be greater than the minimum determination of value as described and agreed upon by the expert panel. During the preparation steps, the experts suggested and validated metrics that determined how the repository would display evidence of value and furthermore prove it was worth the effort of analysis. This hypothesis could not be formalized until the experts had completed their validation of the final metrics.
Assumptions, Limitations, and Delimitations
The primary assumption within this study was that the experts were capable of making appropriate decisions regarding the importance of the work order comments. The techniques used in this study built a consensus among experts; however the originating feedback must have been reliable for the methodology to function properly. Four items required expert opinion: the rubric creation, value assessment metrics, survey validation, and the work order analysis. The rubric required the experts to identify key concepts defining value for the work order comments and provided indicators of value that the experts then rated. These ratings were based upon the experts’ experience and familiarity with the content of each work order comment and the situations from which they were created. They also were required to define and revise metrics for determining overall repository value as well as validate the questions used to assess the scalability of the assessment process.
The assumption was based on the observation that the employees have several years experience in their field and continually work on tasks that provide situations where work order comments are directly applicable. The supervisor’s experience, while not in the field, was also assumed to be sufficient since he manages the tasks and monitors any outstanding issues. A final assumption would be that experts with knowledge of a specific topic or task instance would correct a consensus heading in an incorrect direction. The group technique allowed a single expert to comment on the current average and discuss why a differing rating may preferable in that instance. This would be applicable should an expert have specific knowledge that only his or her personal experience would provide.
This study limited the research to two document repositories. The first was the prototype case, and the second ensured that the methodology was applicable beyond a single implementation. The process would benefit from continued testing, but due to time and expert constraints, the repositories remained at two. The volume of work orders also were constrained to a total of 100 to 150 valid documents. For the same time and expert concerns, volume was limited in order to keep the study timeframe manageable.
The study took place within the domain of public works. Results would be specific to this domain as they were based upon the relevant documents and repositories. The repositories may also have revealed specific characteristics of the chosen public works department. In addition to department specific tasks, there were some instances where localized tasks may have not been applicable to other institutions. In some cases, tasks might have been more relevant to the environment pertaining to this locality. Additionally the subject of the work orders may not have fully represented the entirety of the department. A repository targeted a specific task, and value ratings were based upon the situations described in the corresponding work orders. The methodology attempted to compensate for this delimitation by testing the procedure a second time on a repository with a different task.
This study comprised distinct segments, each with a specific purpose. The terms used in this document are defined as follows.
Group Assessment Technique: In order to gather a common opinion from a panel of experts, the study must employ a group technique. This technique allows for several iterations of peer-assessed revisions as well as preventing bias through anonymity. (Goldman, et al., 2008)
Instruments: After the prototype system is complete, the prototype becomes an instrument within the model. With a larger dataset the researcher utilizes these instruments as a tool to validate the effectiveness of the model on a greater scale (Brinkman & Love, 2006).
Model: The model defines the concept from which instruments are derived. While details may change based on the needs of an individual organization and dataset, the process of data transcription, categorization, and analysis remains consistent (Aggarwal, et al., 2005).
Prototype System: The prototype forms the initial phase of the study. By using a sample dataset, the methodology is formalized in anticipation for use in the second phase. The researcher uses this system in order to validate the information found on the work orders. Core components such as rubric creation, expert group technique and assessment comprise the base of the prototype (Brinkman & Love, 2006).
Rubric: The rubric is a tool designed by the expert panel for use by the subject matter experts. This scaling system outlines the cost and safety categories estimated for each work order entry within the dataset. (Fadel, Brown, & Tanniru, 2008; Goldman, et al., 2008)
Subject Matter Experts, Expert Panel: Within the organization, experts exist that have familiar knowledge of the domain. By utilizing their skills, the value of the work order information is validated through a group assessment technique. (Aggarwal, et al., 2005; Asgari, et al., 2005; Goldman, et al., 2008; Liu & Fidel, 2007)
Work Orders: The handwritten information in question consists of comments found on work orders. Work orders are paper documents used by an organization that target a specific job, work to be done, work performed, and work to be scheduled at a future time. General comments regarding issues noticed by employees are also noted and included in this study. (Scholl, Liu, Fidel, & Unsworth, 2007)
This purpose of this study was to determine if handwritten work order comments contain value. Since documents are created in a workplace but are seldom referenced, there may be value contained within these repositories. Handwritten comments pose a difficult problem due to their inability to be easily digitized and analyzed. In order to test for value within a repository of handwritten work order comments and to find a suitable assessment process, the goal of this study was to answer two research questions. One question focused on using an expert panel to systematically and consistently analyze value with the comments. The other provided evidence that value does exist within the comments.
The following chapters will cover background material and a detailed methodology. The review of the literature will provide topics relating to the aging workforce, expert opinions, tacit knowledge, and character recognition. The methodology will outline the steps required to complete this study as well as define the hypotheses that will answer the research questions.
The results chapter will detail the outcome of the assessment process and the results of the tests performed during the study. The expert panel was required to provide additional suggestions in order to complete the group technique, and these additions will be discussed in relation to their contributions to the final methodology. The final rating consensus and survey responses will form the data that will be discussed in the conclusions chapter.
The researcher will attempt to answer the research questions in the conclusions and connect the findings to the literature. Implications and recommendations for future work will be outlined, and the final assessment of handwritten comment value will be determined.
Chapter 2
The review of the literature covers areas of concern in regards to the aging workforce, paper-based storage, data extraction and knowledge acquisition, difficulties with tactic knowledge, and character recognition. Each topic describes an underlying component that will form the foundation for this study and was thoroughly researched to provide a comprehensive analysis of the problem. An initial area of concern is that of the aging workforce and other conditions that lead to the loss of employees as well as their knowledge and expertise. In an effort to retain knowledge, the literature offers solutions that attempt to collect and interpret the knowledge that may no loner be present should an employee leave. Additionally data may be stored on storage media not in a digital format. This poses a concern since they cannot be easily accessed. These documents comprise a range of formats from formal typed records to casual handwritten notations. The process of analyzing these repositories is examined and compared and solutions or suggestions are offered. The technologies that are used to assist with these processes are also described covering current and future trends. The literature review is divided into sections as follows:
· The Aging Workforce and Experts
· Data Repositories as Potential Sources of Knowledge
· Paper-based Storage
· Knowledge Acquisition from Tactic Sources
· Data Extraction from Handwritten Sources
The Aging Workforce and Experts
Knowledge is lost when large groups of senior employees leave an organization. In the mean time, there is a gap between the knowledge retained by senior employees and new recruits. As Hafida (2008) described in his case study about organizational knowledge loss, there is a need to create a memory of this knowledge. He stated that this is an important step to avoid knowledge loss. Fadel, Brown, and Tanniru (2008) also stated that business processes are constantly changing and through these processes, employees were often distracted and failed to learn new things. As new processes were implemented, employees must have learnt new functions. In an attempt to repair this gap, knowledge transfer was encouraged between peers in order to ensure continued productivity. In an attempt to catalogue senior knowledge and to better facilitate transfer to newcomers, Liu and Fidel (2007) experimented with using a mobile solution to gather knowledge in the field. Three aspects were accounted for including tacitness, information relevance per task, and employee role. Management had been found to be hesitant towards using mobile devices in the field, as knowledge management techniques were viewed as a lower priority than the actual task at hand.
While Liu and Fidel analyzed on-site environments, Hafina (2008) attempted to study the applications within a virtual setting. Virtual organizations are created for a temporary need and assembled quickly. This collaboration was designed to provide information, but there was a need to retain this information for future effectiveness. The case study performed by Hafina tested the evaluation of structures after an earthquake. Due to the necessity of quick action and the inability to gather experts onsite, a virtual environment was set up in order to collectively analyze the situation. The CommonKads methodology was used to initially model the knowledge management process. CommonKads was designed by Schreiber, Wielinga, and Breuker (1993) and was intended to segment knowledge into components that could be more easily analyzed. This model had some limitations such as lack of organization for external entities, lack of coordination and time loss due to language translation issues. With these limitations identified, extensions were proposed to overcome the obstacles. Of primary importance was the need to treat each organization as a separate entity despite the collaboration. Since each entity had different requirements, they could not be combined. Additionally a dictionary of common terms and concepts was proposed to assist those who do not speak the same language. This provided a way to share the most basic information quickly and efficiently. Overall the case study showed promise towards collecting information. However Liu and Fidel (2007) found that while younger employees are willing to share knowledge during the course of their work and continue building an active knowledgebase, senior employees were more hesitant. This was important to note, since the specific information collection procedures must have been tailored to their needs. Senior employees were also the target group for potential knowledge loss, so it was important to ensure that they were active participants.
Research between and within disciplines was difficult to obtain in the field of digital government work despite being of interest. By gathering the contributions of researchers in varying but related fields, Scholl, Mai, and Fidel (2006) hoped to compile a collection of processes that addressed the integration of workflow. In a joint paper, Scholl, Fidel, and Mai (2006) formed the groundwork for Liu and Fidel’s (2007) research by experimenting with mobile applications in order to improve collaboration. While still in an early stage of development, the mobile applications promised increased efficiency and productivity. The study focused on the difficulties of fieldwork and how the mobile methods addressed these challenges. Data was collected through the field studies and observations of the employees as they performed their tasks. This data included performance and communication elements. The mobile solution initially ran into technical problems; flexibility and synchronization being the most prevalent. The researchers found that short cell phone calls were in cases found to be more efficient, but the process bypassed the mobile implementation. Five organizational problems were found which related to proper field training, business process design, compensation for the added effort, lack of standard operating procedures, and trust issues between management and employees. The authors suggested recommendations in order to initially improve these conditions. Technically, the mobile application needed to be built around the field work operations, rather than being added to it. Ownership of the data should have been transferred to the employees in the field, rather than reporting the raw findings back to a central office. This would allow the knowledgeable work force to make some decisions that were relevant to the gathered data.
Fidel, Scholl, Liu, and Unsworth (2007) continued the progress performed by Liu and Fidel’s (2007) by implementing a fully mobile fieldwork operation while assessing the efficiency of the system. The research was based on a perceived need for timely information within the field and attempts to better understand the interaction between the employees and their dependence on information. Their initial test case proved to be very successful after building upon previous implementations of wireless applications. However upon further implementations, the systems were not as successful as the prototype case was found to be an ideal match and could not be generalized. The authors used a Cognitive Work Analysis framework to find variables as well as their interaction. This was found to be a beneficial process since identifying variables was improved when addressing the relationships that they form. By forming a high-level analysis of the workplace, the elements forming the field work were given equal emphasis. Additionally the variables were ensured to be relevant since they had been discovered in the field on valid tasks. This framework then formed four research questions that described the tasks, organization, social concerns, and human concerns. The approach used a case-study method which concentrated on specific tasks in the field. Each task was considered a unique case even if two employees were responsible for the work performed.
In a follow-up paper Scholl, Liu, Fidel, and Unsworth (2007) further analyzed the benefits of onsite automated wireless communication through a developmental case study. This automation promised gains in efficiency and productivity, but faced technical challenges. Work performed in the field may cover broad subjects and automation of this diverse fieldwork had not produced as many gains in productivity as office or shop work. The automation had not worked as well as hoped since many forms had been directly transferred from office and shop environments without regard to the different nature of onsite fieldwork. This field work could be divided into three sections: highly structured (police work, rigid procedures), primarily structured (construction, programmed, but with exceptions if needed), and semi-structured (maintenance, disaster recovery, frequent exceptions and interruptions). While some office type procedures might have formed the backbone of fieldwork automation, basic wireless communication techniques might present alternative solutions that would be more beneficial. Other downfalls to automation acceptance would be the lack of user support. In environments where work is not as structured, employees were often preoccupied and did not wish to do anything off the main task. This work also involved a degree of tacit knowledge, which is more difficult to define and utilize with many communication procedures. Automation also posed technical problems across environment and time constraints.
A common consensus from the authors stated that effective information gathering is best performed in the field. Senior employees form an important target audience since they are in a position to possess the most knowledge as well as being closer to retirement. While younger employees are more apt to document their skills and experience on an ongoing basis, gathering existing knowledge from experienced individuals has proved to be a challenge (Liu & Fidel, 2007; Scholl, et al., 2007).
While technology can be used to gather knowledge from experts, collaboration methods have also been found to be beneficial. Traditional collaboration models working with shared documents use a local copy model that distributes the document to each user. Computationally expensive processed are then needed to ensure that the master document is in synch with the other modifications. Preston, Hu, and Prasad (2007) proposed a system that would solve this problem, not by copying the entire document, but dividing it into sections. Each section is locked and avoids the need for consistency checking, while still allowing the same document to be modified by multiple users. The system achieved additional efficiency by avoiding numerous broadcast messages in favor of a server managed scheme. The server did create a bottleneck, which could be viewed as a negative aspect. Future work proposed a peer-to-peer structure that would combine the efficiency of the system without a centralized server to maintain.
Within organizations, there is a conflict between an employee’s need to structure their own procedures and the company’s desire to standardize. Makolm, Wei, and Reisinger (2007) created a project that attempts to provide employees with appropriate knowledge while minimizing additional overhead. Similarly Bossen and Dalsgaard (2005) describe a situation where employees created a parallel system to the implementation designed by the organization. This parallel system was preferred over the official one and was eventually adopted by the administration.
Makolm, Wei, and Reisinger’s (2007) implemented a context sensitive monitoring system to intercept user input and learn their behavioral processes. This process was broken into three phases: initial observation, developing discovery patterns, and supporting the knowledge findings. For the first phase, an event trapper, which records keystrokes and mouse clicks, stored these findings into a log. The combination of certain moves was then combined into event blocks in order to reduce redundant data. This allowed for the creation of rules that translate into proper sequences. These sequences were initially mapped manually, but the process could become automated after a learning phase. In the test case, users were found to need to know where information was stored, how it can be found, and the relevance of what it ultimately returned. After testing, the returned information was found to be related to activities on and off the computer, tools used, distractions, informational sources, and applications.
Employee acceptance was not as favorable in Bossen and Dalsgaard’s (2005) research. The authors described a case where administration implemented a KM system, but it went unused due to a competing employee driven system. The company had expanded to double its size in only two years, and during this time they faced trouble training employees and ensuring that knowledge was properly transmitted. Initially recruits could work with existing employees, but due to the rapid growth half of the employees were new making this not feasible. Additionally, the knowledge transfer process between project handovers was lacking and knowledge loss was occurring. Despite systems in place to document knowledge, they each possessed a learning curve to use. With these barriers, the company implemented a central system that would manage all knowledge.
Bossen and Dalsgaard (2005) stated that the company’s primary purpose was to function as a document repository. Employee turnout, however, was low and most documents were submitted by a small set of employees. This in turn provided less incentive for others to contribute who then proceeded to concentrate on their normal duties. Updating a repository for documentation purposes was not seen as a priority. Despite the disuse of the system, portions were expanded into parasitic sub-systems that utilized the central database, but bypassed the general interface. The reason the general system failed, was the fact that it lacked specificity and omitted clear goals, while the specific needs fulfilled by the parasitic system remained useful. Also, tacit knowledge nature required interpretation before becoming explicit written information. This information may lose detail, specifics, and context. Information in this organization may have also became outdated or irrelevant over time due to the nature of their work. In the end, the parasitic systems were officially accepted since they provided valuable insight to knowledge management systems that were beneficial to employees.
In a more active effort, Wikis have been implemented in organizations in order to store and access data. While this structure has primarily existed in a casual environment, moving to a corporate structure raises issues with maintenance and oversight. A Wiki is conversational tool that encourages contributors to tie knowledge to a specific context. Hasan and Pfaff (2006) covered a specific case where a Wiki was disallowed after management voiced concerns over the implementation. The first issue was that organizational structure might be affected. If everyone had equal ability to share knowledge, the traditional hierarchy breaks down. Centralized solutions were also seen as preferable since the organization could govern them more easily. Wikis also pose social concerns. Vandalism is an issue to any freely editable system, especially since the Wiki structure is designed for intuitive manipulation. Recognition is also limited in a Wiki environment. On one hand, some may feel that their contributions are not visible, while others may contribute important information, but the overall volume portrays their work as insignificant. Additionally there is a great need to verify data since information is added immediately and may not be accurate. There are also legal concerns over intellectual property and libel.
Reporting on a successful Wiki implementation, Raitman, Augar, and Zhou (2005) described a classroom use that benefited from a Wiki. The authors performed a survey to analyze user opinions about their use of a Wiki. Online students were targeted for this survey since the course had required a Wiki for all student and instructor collaboration. Positive effects of the Wiki included: ease of use and a small learning curve, beneficial communication, and positive social interaction. Unlike the employee reactions in Hasan and Pfaff’s article, the semi-anonymity of the contributions helped the more reserved students collaborate in a more comfortable way. Negative aspects concentrated on possibilities of vandalism. Additionally despite the ease of collaboration, the students felt that communication was not always the same as conversation. This created a situation where face-to-face communication would have been preferable.
Wiki formats can also be combined with more traditional structures. In order to enhance an existing e-learning platform, Giannoukos et al. (2008) proposed a mixed system that includes interactive forums and a Wiki structure for long-term storage. The forum is implemented for student use in order to facilitate collective discussion and the generation of information. Course material is distributed in a traditional manner; however the students then discuss the topic through the forum. While general forums are provided, the system designates a specific collaboration forum for this purpose. The hypothesis is that while the Wiki format is suitable for retaining collaborative contributions, the submission process is often unstructured and unfocused. The forum discussions allowed the students to finalize a thought process before the content is then stored in the Wiki. Additionally the information went through a more thorough revision process, which is needed in a smaller collaboration groups such as a classroom. Much like Raitman, Augar, and Zhou’s (2005) case, students who contributed were found to have higher grade averages than those who did not participate at all.
Network performance plays a role in the effectiveness of these virtual environments. Characteristics such as latency and bandwidth may negatively affect a user’s ability to efficiently use a virtual space. Rodrigues and Chaves (2007) described an experiment where these parameters are controlled in order to compare the experience of a simple virtual test among trainees. They hypothesized that performance would degrade as the bandwidth was reduced and latency increased. By using an objective means of measuring completion time as well as a subjective evaluation of users’ experiences, the researchers were able to compare the performance and variables. After the experiment, the hypothesis was proven true, however latency was found to be less of a concern than a reduced bandwidth.
While virtual environments provide some challenges, collaboration in the field also poses some unique problems. Bortenschlager, Reich, and Kotsis (2007) targeted the problem of collaboration in a mobile and unstructured environment, while Sakai et al. (2009) described the barriers that multiple languages introduce. The authors stated that while technology has advanced in traditional settings and provided more opportunities to communicate, environments without a fixed location have had difficulty with efficient collaboration. The primary difficulty is the inability to utilize new forms of communication, and as the researchers found processes can take longer to complete despite the technology advances. Bortenschlager, Reich, and Kotsis proposed a layered system in order to better utilize this environment. The communication layer was structured upon the peer-to-peer model inherently possessing a decentralized structure and some resistance to failure. The unstructured nature also allowed for asynchronous behaviors so communication is not reliant on space, time, or direct association. To manage the asynchronous communication, a supervisor entity was used to organize the tasks. This supervisor was responsible for overseeing the goal and managing the information in a way that achieves that goal, similar to how a distributed computer system is able to divide a workload. The tasks were then redistributed back out to the individual entities where they could be completed.
Similar to Hafida’s (2008) study, this approach was applicable to emergency situations where structure organization is not always possible. These situations often were comprised of planning, response and recovery, which addressed the problems and provided solutions. The complexity continued as the knowledge of the situation decreases. Knowledge of the activities and time/place played a factor in the basic categorization of events. When both scenarios are known, there was little urgency, but when there was no knowledge as to the time or place, specialized teams must work efficiently in order to respond. When knowledge of neither the activity nor time and place was present, it is this situation where new applications and research must provide best practices. Collaboration at this time became crucial.
Bortenschlager, Reich, and Kotsis (2007) described how emergency situations may cause complexities regarding the environment, but such issues might occur even in relatively common settings. Mobile users in an organization often did not have a fixed office or central workspace. Due to their job specifications, they were continuously moving to different locations but still needed to remain in contact. Technological advances in mobile devices have increased their usability, but there are still limitations with a device that interferes with the employee’s regular task. This is especially true when a user needs to be hands-free. Sammon, Brotman, Peebles, and Seligmann (2006) proposed a solution that utilizes a small hands free device with voice recognition in order to eliminate some of the traditional drawbacks. This solution should complement an employee’s regular duties while allowing communication. After a test with 35 employees, the users found their jobs to be more efficient and productive. Approval for the system remained in the 70 to 80% range for attributes such as communication and perceived job performance. There were some problems with the technical aspects of the prototype system, but that did not reduce the apparent effectiveness.
Environment is one area of concern, but while collaboration has the ability to enhance learning, it poses problems when multiple languages come into play. Despite the barrier, multilingual collaboration is often needed in critical environments. Sakai et al. (2009) noted that in order to be effective, the tools must provide a level of customization to adjust for cultural differences. Current portal solutions, although allowing collaboration, were found to be too rigid. To overcome this difficulty, the authors proposed a solution that would allow interchangeable parts. This solution started with a layered approach that bridged the gap between simple language translation and the applications needed for effective collaboration. Building blocks were then added in order to provide tools. These building blocks were divided into three categories: basic, advanced and customized. Basic tools allowed minimal connections, while advanced tools provided resources for more complex language connections. The customized tools formed the final bridge that allowed functional collaboration. In order to test this system a school was chosen containing fourteen foreign students. The series of building blocks allowed for both a faster programming cycle and a more intuitive user process. The basic blocks assisted with translation, and the advance blocks enhanced the language dictionary. The quick turnaround time for the system, consisting of six weeks, was found to be an indicator of success.
While collaboration among peers has been shown to be beneficial, experts play a role in analysis when qualified opinions are needed. Expert panels can provide assistance with estimation, categorization, and evaluation. By using expert opinion, researchers can benefit from qualified assessments on specific topics and with fewer participants. Group techniques are often implemented in order to arrive at a consensus, at which point the combined expert opinion can be applied to a situation (Aggarwal, et al., 2005).
Expert opinion can also be combined with traditional decision systems such as casual maps, decision trees, and neural networks (Aggarwal, et al., 2005; Baglioni, et al., 2005). Baglioni, Furletti, and Turini outlined how data extracted from a database is most useful when properly categorized. This categorization could be achieved through automated procedures, but the authors found that some knowledge extraction is better suited for expert opinion. Two methods of expert assisted decision making were described through causal maps and decision trees. Causal maps were created in an attempt to replicate human-like thinking; a process designed to form relationships tying together similar concepts. This method was later improved in order to strengthen the relationships by assigning probability to the links. In the process new relationships also have the possibility of forming.
Decision trees however require predefined classification, and then build upon these groups to form new classification. By recursively dividing concepts, the tree can be built and applied to unknown entities. The threshold of classification division can be adjusted in order to prevent the tree from being too diverse. An overly diverse tree negatively affects its usefulness since concepts will less likely be related. A tree lacking diversity also poses a problem since the classification will not be accurate enough. The threshold must be set to balance these two situations. While both methods track relationships, the research indicated that some relationships are more complex than connecting one entity to another. There were instances where two links can be formed from a single rule, further altering rules as more is known about the system. Within the test case described by Baglioni et al. (2005), a sample store was chosen to populate the initial dataset, while another store would then use the generated rules to build its dataset. By using an expert supervised method, the rules were guaranteed to remain applicable to dynamic environments and remain current. Additionally, the prior data did not all need to be from sample data. Expert knowledge could assist with the initial dataset by providing more detailed rules gathered from personal experience. For example, if a concept is unique to the test case and absent in the control dataset, some rules may not be sufficient. Supervisory intervention can update the rules in the control process to allow for these situations.
In a similar test, Aggarwal, Yogesh, Pravin, and Manimala (2005) compared computer based estimation techniques such as regression and neural networks to an expert committee, hypothesizing that they would provide better results. The authors tested the problem of software effort and resource estimation. Due to the inherent complexity of coding, especially within the early stages when little is known about the project, estimation is not straight forward. Two metrics were proposed for determining the size of programming code: lines of code and function points. While lines of code provide a fixed value that can be measured, there was variation in the weight and importance of each. Function points outlined the problems that need to be addressed by the program. While regression and neural networks were found to produce the strongest results, a combination of these methods yielded an expert committee model producing stronger results than either of the individual methods.
Data Repositories as Potential Sources of Knowledge
When information is needed, repositories are often used to store and retrieve documents. As documents accumulate, they are placed in locations where they can be referenced at a later time. Repositories face several problems such as difficulties with management, efficient searching, and dataset volume.
Managing repositories becomes an issue of concern as the volume of documents grows. Technical barriers and workflow problems must be addressed in order to form an efficient system that is beneficial to all users. Mikeal (2009) described a system used to manage dissertations for universities throughout the state. In an effort to adapt to the needs of the universities that would have had to engage in this collaborative effort, the authors proposed four strategies: participation, flexibility, scalability, and the ability to be easily integrated. While participation was found to be essential, assigning metadata and formulating a workflow were critical components to the whole system. Universities have differing schemes for their metadata, so the submission process needed to be strictly regulated in order to result in a repository of homogeneously organized documents. Preservation was also important when managing these documents. To solve this problem, the authors formulated a methodology that distributed the contents into redundant storage across the state. Both the documents and metadata were equally distributed, and managed by a central system.
Often documents are not part of a one-way submission process, but instead are managed and continually altered by many users. In addition to the volume of documents, there may be several repositories in use containing multiple copies of the same document. Muller (2007) described a situation where these documents may become unsynchronized due to multiple alterations in one repository that is not reflected in the others. The burden of collaboration was moved from the system to the users, where mistakes and inefficiencies became more prevalent. When documents become unsynchronized, the users must spend more time researching the location of the most up to date document or risk significant data loss. Muller implemented a unified system to combine the repositories in an organization. This system provided users with real time status updates about the system, and prevented them from having to perform these maintenance tasks on their own. Wong et al. (2007) faced a similar problem when managing design documentation. New designs required knowledge and details from previous versions, so the ability to efficiently access these documents was critical. In the aero-engine industry, repositories were distributed throughout the world. With a recent shift from selling products, to providing services, it had become increasingly more important to understand the required engine maintenance. Wong et al.’s study primarily targeted the common difficulties encountered with non-textual data. The system initially used to manage the documents, would only work with text and could not reliably process numerical values and arithmetic. This was then moved to an SQL style operation which was found to work more efficiently as well as interface into the standard relational databases found throughout many of the repositories.
Searching within repositories posed management concerns as well. As volume increased, the effort required for searching became more complex. This was more evident in self-archived repositories, since they may have not been organized as efficiently. As time passed and more content was added, the structure became more unsuitable for efficient indexing. For local users, this did not pose an issue since most were familiar with the layout they had created. However users without firsthand experience with the repository would encounter difficulty finding the desired document (Rader, 2007).
One proposed solution to the problems with self-submitted repositories was through real-time data capture at the time of submission. Aman and Babar (2009) proposed a system that captured data from common applications such as e-mail and word processors. Since these methods of documentation and communication were commonly transmitted casually, interception was found to be an important way to capture this data into a repository without the users having to manually archive the information. By reducing the effort required to document procedures, users were able to focus on other tasks, while still having a relevant repository for reference.
Searching repositories employs active methods to find the desired criteria. Fu et al. (2007) describes methods to search for experts within a repository. Finding appropriate expert resources had been found to be difficult but necessary given a need for knowledge or collaboration. Unlike Francesconi and Peruginelli (2007), Fu targeted the more complex needs of defining human characteristics. While previous expert search models had been based originally on documents (Canfora & Cerulo, 2006), Fu proposed a model centered on possible candidates. Traditional document models mined data from existing sources, but candidate models pre-compiled classification based on the corporate repositories. By listing terms related to an expert’s documentation, the researchers could assume that these terms would match the abilities of the expert. Through queries, one should be able to return a match for an appropriate expert based on relevant search terms. Additionally, Fu stated that this process is flexible and could be applied to other domains such as software and multimedia.
Research into searching document repositories is made more complex when repositories were not centrally located. Francesconi and Peruginelli (2007) utilized a portal to find and access legal document repositories. In the past legal documentation remained in physical form, even as other fields moved towards digital distribution. As legal resources moved to electronic repositories, there was a need to properly and easily access them. Francesconi’s method implements a portal technology to capture and organize metadata from separate sources. These sources range from formally structured scholarly databases to informal private web sites. Formal sources are easily mapped to a standard set of metadata, while informal sources require metadata generation based on the content. After standardization, users are presented with a single point of entry when searching for legal documents. Bolelli, Ertekin, Zhou, and Giles (2009) expanded upon repository searching by analyzing the time segments from the topics. Like Francesconi, their goal was to organize the metadata associated with documents. By analyzing the dates associated with key terms, trends could be found that would help with future searches, as the relevance of a topic would be limited to its peak timeline. The evaluation demonstrated that this process would accurately tie themes to authors as well as outline evolving topics.
One relevant implementation of a collaborative repository is within an open source environment. In these repositories, information is both deposited and collected by users in order to complete a project. Open source applications benefit from the collaboration and creativity of a diverse team, but lack the structured documentation that more formal projects possess. Forming a structured foundation for information becomes an important task so that users can build upon the past work by others, as well as document their changes. Version control, tracked changes, and delegating contributors are some ways that Canfora and Cerulo (2006) listed as required achievements for a successful open source repository. Of particular interest was the process of seeing how the application was developed over time as well as the ability to identify developers with a known skill set. While Fu et al. (2007) outlined an active method to search for experts, Canfora used this repository to passively select programmers for a specific project and created a database of these developers based on their abilities.
Rather than using a traditional repository to archive open-source documents, van der Merwe and Kroeze (2008) described an initiative using an open-source mindset as its core foundation. The case study performed by the authors outlined the benefits and drawbacks of a system managed by its users as a self-archiving repository. Benefits of such a system were dependent on the organization of the contributors. Projects in this study with a need for shared knowledge had reduced development times and ultimately were more successful. Additionally the project was not affected as much when a key member left the team, due to the organization of the self-deposited knowledgebase. The authors did see some drawbacks however. A dynamic system should primarily be used for an active collaborative effort, as long term document warehousing would not effectively use the systems strengths. In the same respect, long term preservation was found to be a difficult challenge for this and other digital repositories due to the nature of intangible documents.
While many repositories are maintained by the originating organization, the World Wide Web provides additional sources and a wide range of topics. Through extraction and anchoring remote documents, local repositories could benefit from the increased availability of topics (Banerjee, 2008; Codocedo & Astudillo, 2008). With the added benefits, there were also some drawbacks such as volume, poor formatting, and organizational concerns (Dey & Haque, 2008). Document unavailability over time also formed a key concern when using repositories that are not directly managed (Nikolov & Stoehr, 2008).
Banerjee (2008) and Codocedo and Astudillo (2008) proposed methods to efficiently utilize the resources provided on the World Wide Web. Banerjee described a method that data mined documents from a chosen web repository and extended the text classification of a local resource. Since the text extraction was performed locally after downloading the documents, the speed of the reclassification is greatly improved. Also the remote documents would not degrade a users experience if the contents were found to be irrelevant, since they were supplementing a functioning repository. While there would have been some wasted overhead, there would never be a case that results in less data. Codocedo addressed some of the inherent problems with web-based archives. While some large targeted repositories exist, many documents were spread across the internet without formal organization. Documentation was also in a variety of formats such as blogs or Wikis, and in non-textual forms such as images and video. The increased volume was largely attributed to a user’s ability to create their own content as well as contribute to the web’s resources. Assigning proper metadata to content was often not a priority for a content creator, since many web tool and search engines would perform that task. Accessing the content directly, however, posed organizational problems if this metadata was not present.
Codocedo and Astudillo (2008) proposed an anchoring system for web documents, outlining four areas: extraction, indexation, integration, and information creation. The key component of extraction was the process of creating knowledge units from the documents. The units contained the content determined to be important by the system and was linked back to the originating document for context. Once the units were indexed, they formed a homogeneous group that was more easily integrated into the core system. The authors noted that even foreign language documents were easily indexed since the resulting knowledge units would be in one language. The final step, information creation, used the knowledge units to tie together similar ideas and form new statements that were not in the originating document. Knowledge units may have had some difficulty being extracted, mainly in sources that were poorly formatted. Informal text comes from many sources, and possessed no guidelines or quality control. Traditional language interpreters would not normally understand misspellings, poor grammar, and incorrect punctuation. Thus extracting knowledge becomes a complex process.
To overcome the difficulties associated with informal text on the web, Dey and Haque (2008) proposed a hybrid system that is trained to learn how to read informal text and then extract items of importance, which was then used in a traditional manner. The purpose of Dey’s case study was not to create clean text from a noisy source, but rather to eliminate erroneous logic detection when opinion mining. Once items of knowledge had been identified, they could be analyzes and combined into another resource. Informal texts also have the possibility of becoming unavailable. Since the World Wide Web has no set structure, documents and sites may be added or removed without notification. Documents in the form of PDF files form a majority of online scholarly articles. In a similar manner as informal websites, these documents may disappear at a given time if they are not based on a structured repository. Nikolov and Stoehr (2008) looked at the rate of unavailable PDF documents on the web over time when hosted on private websites. Through an empirical study, the authors analyzed documents identified by a search engine and plotted the rate of disappearance over a five month period. A volume of over 700,000 documents was found to lose 10% over the five month period. A total of 8.4% were permanently lost, as they had no remaining cache in the search engine’s records. Nikolov stated the claim that more rigorous archiving is needed to protect scholarly documents from being lost permanently.
A repository containing a large volume of documents may pose a problem with representation and efficient handling. A large dataset will require a greater level of effort to extract appropriate information and knowledge, determine duplicates, and achieve collaboration. Data extraction and estimation can provide an indication as whether a user can successfully utilize a portion of the repository. Baillie, Azzopardi, and Crestani (2006) described a method of estimating resource descriptions within a repository. If the descriptions of the estimation are of high quality, the descriptions would provide evidence that the entire repository is most likely valid as well. However, some degree of prior knowledge was required by the administrators in order to properly pull sample descriptions. Baillie’s study demonstrated that topics and domains do not need to be similar. Additional research contributed by Pasca (2007) found that heterogeneous domains can in fact strengthen the extraction and estimation process if successfully implemented. Pasca found that in some cases within these domains smaller portions of data can be more relevant than the entire document. This posed a problem since many documents ran the risk of exclusion at an early selection stage before the contents were properly mined for data. In an attempt to provide a solution to this problem, Pasca described a process to create a local offline sub-repository to store facts. Users could then run the queries against this repository in order to match fact entities, which would in turn link to the full article. While there was overhead present in the fact gathering process, the results for the users provided both a time savings and increase in relevant returns. Since the facts were also not tied to a single document, they could link several sources together and provide a user with several documents matching the desired query.
In certain cases estimation and extraction may not be appropriate if the documents must be searched in their entirety. Traditional search techniques would not work on these repositories due to their size and distribution. In these cases distributed systems could be used to balance the increased load requirements as well as remain scalable to respond to changing volume (Griesemer, 2008). Comprehensive tagging systems could also help with this process. Tags provide metadata for documents across very large repositories and are often user submitted. This would allow simultaneous collaboration among many contributors, so that the burden of labeling would not fall on a limited group. The process would result in a repository that is potentially labeled in its entirety rather than a small extracted or estimated portion. However this process could be prone to inconsistencies. Since many users collaborate on the tagging process, the labels used may not be standardized (Forman, Eshghi, & Chiocchetti, 2005; Forman & Kirshenbaum, 2008; Wu, Zubair, & Maly, 2006).
Due to the portability and tangible nature of paper, it does pose some security concerns. As Fujii et al. (2008) describes, sensitive paper documents do not possess the intricate security restrictions as those in the digital domain. Physical paper could be printed and then carried out of a secure location with relative ease. In order to address this concern, copy machines have had additional security measures installed. Rather than printing directly to a piece of paper, the contents of the source document must be sent to an external sever for verification, then passed back for the final output. While this does cause some system performance issues, the benefits of disallowing unrestricted copying were found to be an acceptable compromise.
Despite the advantages digital documents provide, paper in some environments is unlikely to phase out. In settings such as an airplane flight deck, communication and tangible documentation are necessary for pilots to perform their job. Nomura, Hutchins, and Holder (2006) described the need for physical paper during the course of a pilot’s work by monitoring a simulated flight procedure. After analyzing the role paper played, the authors determined that paper is integral to the pilot’s work because it is flexible, tangible, customizable, and portable. The ability to handle paper allows pilots to rearrange them in their physical space, as well as share the document with a co-pilot if needed. Important notations that reflect relevant tacit knowledge can be quickly highlighted or added as an annotation. The paper also is easily carried with the pilots assuming a small volume of documents. The authors conclude that paper is an ongoing necessity rather than an archaic form of documentation that hadn’t been updated.
AbuSafiya and Mazumdar (2004) expanded upon the idea that paper will never be entirely replaced by digital documents. While a paperless environment may be ideal, it is not always feasible. In contrast to the proposal by Norrie et al. (2005) for supplementing paper with digital, AbuSafiya and Mazumdar suggested integrating paper into digital databases. The authors argued that not every paper document is a result of a digital file or a placeholder for future digital transcription. The authors found that paper documents hold some original value that cannot be replicated through purely digital methods. One of the problems with paper archives is the inherent lack of efficient organization. Paper was traditionally managed through manual procedures, while digital documents could be processed on a computer in a more efficient manner. Jervis and Masoodian (2009) used the enhanced organizational abilities of a computer to digitally manage physical documents. Rather than digitizing paper for this procedure, paper was left as-is, and a framework was built around the existing folders. Using electrical contacts on the folders, a computerized database system was able to determine the location of folders, as well as provide feedback to the user via LED lights.
In other environments, paper may be a personal preference that justifies its use. Recognizing the use of tangible paper based media has revealed a preference for documents that can be handled despite the advantages computers provide for indexing and categorizing. Both Döring and Beckhaus (2007) and Norrie et al. (2005) researched the ability to allow both paper and digital to co-exist while complementing each other. Döring and Beckhaus proposed a system that would allow users to handle tangible media as they are accustomed, while a computerized aspect tracked each and performed organizational measures. This solution improved upon the limitations of traditional tangible media while allowing greater organizational flexibility. The handling methods had not been in use years so persuading users to convert to another means was found to be difficult. The authors agreed that a computerized system aided with organization, but suggested that paper-based methods would help with creative aspects. By allowing each system to coexist, they found that productivity increases with minimal resistance to change.
Norrie et al. (2005) discussed the advantages of paper documents, but investigated merging the ideal properties of both physical and digital media. The authors proposed an interactive paper document that would combine the convenience and portability of paper, with the services and information provided by digital means. In the proposed technology, paper documents would retain their traditional functionality but enhancements would allow additional benefits. Simple markings such as barcodes or the dot-based Anoto technology would not detract from the paper experience. However with the appropriate supplemental technology, a device could identify the physical document and return more detailed or specific data to the user. The degree of detail could be as broad as the entire document or as narrow as individual statements. The primary achievement would be the co-existence of the experiences.
Further describing methods to merge paper and digital documents, Steimle (2009) proposed a system where a user’s input was captured in real time through the use of a traditional pen and paper. In contrast to the studies by Döring and Beckhaus (2007) and Norrie et al. (2005), the paper documents were not tagged or linked, but rather directly integrated into a digital system at the time of creation. Through the use of case studies, the authors were able to collect their findings and describe the core interactions needed for a pen and paper interface. Interactions found to be the most important were: inking, clicking, moving, and associating. Inking describes all writing, drawing, and gesture input that portrays one item or event. Clicking involves taps that are tied to events, while moving described the reorientation and organization of the paper media. Associating is the linking of more than one page and inferring the relevance of data amongst the paper. These known interactions were used to implement digital capturing methods to record data and perform associations. Their findings supported the processes necessary to yield beneficial digital results while retaining the ease of use with traditional paper.
Liao, Guimbretière, Hinckley, and Hollan (2008) further analyzed paper to digital processes. Rather than use exact copies of paper documents like Steimle (2009), paper acted as a proxy between digital documents via gesture inputs. The annotation process relies on gestures providing commands through the paper then interpreted by the host system. Through the use of a case study, the combination of annotations and digital interaction was found to be beneficial to a user’s experience. Users found that their experiences resulted in the natural use of traditional paper handling, but still were able to enhance this experience by adding in advanced processes that could only be achieved through digital computing. This could be further enhanced by lessening the restrictions on the use of the paper copies. By allowing users to use paper or digital as they see fit based on the situation, a system would allow for greater flexibility. Weibel, Ispas, Signer, and Norrie (2008) also described use of the a digital pen in their PaperProof application. Similar to Liao, Guimbretière, Hinckley, and Hollan’s study, paper was used as a medium between digital cycles. From a user perspective, they could edit a digital copy, or print it on paper to annotate away from a computer. However unlike Steimle’s (2009) study, the paper documents did not have the same weight as the digital masters. As gestures and annotation are initiated by the user, the corresponding commands were received by the host computer and applied to the master copy. This system provided the freedom to use the method best suited for the user’s needs, while only retaining one master copy, and also allowing for simultaneous usage among several editors.
The merging of paper and digital media posed some problems when the documents need to be tracked and organized. Konishi, Furukawa, and Ikeda (2007) proposed a document management system that correlates traditional paper documents with digital counterparts. Like Liao et al. (2008) and Steimle (2009), the authors utilized the Anoto digital pen in order to capture handwriting in real time. The Anoto pen uses specialized paper with a unique dot pattern to determine page identity as well as position, which is then used to recreate the handwriting. An internal clock also tracks the timeline of document creation. By using the author’s system, physical documents were printed from digital copies, and digital copies were made when a user writes on the paper with a specialized pen. This workflow allowed for accurate document tracking and enabled users to behave in a more natural way when documenting while capturing nuances found more often in handwritten input.
In most cases, digital pens may interpret annotations or gestures, but all processing and feedback is performed at a later point on a computer. Systems such as the one proposed by Weibel, Ispas, Signer, and Norrie (2008) relay commands instantly to a host system, but useful feedback for the user is often lost in the process. Song et al. (2009) advanced the use of digital pens by allowing for instant feedback. The use of a projector matching the orientation of a paper document provided visual feedback for any modifications. Much like the previously described Anoto pen implementations (Liao, et al., 2008; Steimle, 2009), handwritten text and commands would be possible, but the ink portion could be eliminated. With a visual feedback system, projected images would allow for text, gestures, as well as interfaces more often associated with desktop applications such as buttons and menus. Other features such as layers and alternative views would be possible and allow for an enhanced experience. The users were able to work naturally on a large canvas with a familiar input device, but the limitations of fixed markup were removed in favor of a dynamic and customizable interface.
Such systems do not need a traditional input device. While a pen has been found to be a natural tool and well suited for paper-based input (AbuSafiya & Mazumdar, 2004), other devices have been found to perform specialized functions. Terry, Cheung, Lee, Park, and Williams (2007) proposed a system to work with existing paper documents in an intuitive and graphical manner. By using two wedge-shaped devices, a user could frame an area of interest on a paper document, which will then correspond to the appropriate view on the computer display. In the evaluative study performed in this article, users did not adapt as easily to the alternative input devices, as they expected traditional computer peripherals, but soon were accustomed to the change. Also in this study, architectural designs were used. These paper designs had associated digital counterparts with varying levels of detail. Framing a small portion of the design would, in addition to zooming in on the details, load a higher resolution copy of that area so that no degradation of quality occurs.
Knowledge Acquisition from Tacit Sources
While explicit information can be gathered from document repositories, knowledge is often gathered through tactic sources. People possess experience and logic that often cannot be replicated in documents and formal repositories. When relevant knowledge is needed, different methods must be used to convert this knowledge into explicit information if it is to be retained. Observation is one method that is commonly used, but active attempts such as interviews and knowledge sharing sessions have also been proposed (Chklovski, 2005; Delen & Al-Hawamdeh, 2009).
In some cases where keywords are impractical or do not extract the desired knowledge, expert panels are consulted in order to utilize field expertise when analyzing documents. A study performed by Asgari et al. (2005) identified folklore within an organization as an important subject to be captured and utilized. Folklore in this case consisted of organizational statements relevant to the daily workflow. The employees had used these statements, but there was no agreement on their general value. From a document base consisting of notes, a panel was asked to assess the content of notes and rate its validity within the organization. Through surveys and discussion, the authors were able to form final consensus among the opinions. While expert opinions are important for knowledge assessment, there are some areas of concern. Cao and Compton (2005) identified issues through analysis of knowledge acquisition from experts’ classification of several topics. Definitions within the topics ran the risk of error due to overspecialization and overgeneralization. Topic classification was found to be most appropriate when the definition included enough description to be valuable, but not so much that it included portions that were of minor significance.
With the frequent use of paper as a medium, there is interest towards extracting knowledge into a more manageable format. While structured data is much easier when it comes to manipulation and extraction of knowledge, the informal texts may also contain items of importance. The drawback to targeting informal text originates from difficulty both in terms of transcription and interpretation. If a document is handwritten, the process of converting it into machine-readable text is the first obstacle and one that will be solved as technology improves. Once the text is read, another problem arises. The data on informal documents is usually not of a strictly factual basis. Carenini, Ng, and Zwart (2005) discussed this situation as it relates to customer reviews. This knowledge was generally considered important for organization knowledge, since it directly gathered end user input. Many opinions, suggestions and complaints were found within reviews, so the authors found extraction to ultimately be beneficial. While this situation has its unique attributes that must be considered such as product features and review criticism, the techniques described might have been applicable in a general sense to any informal data extraction.
The primary focus of Carenini, Ng, and Zwart (2005) study was based on automation and intelligent learning capabilities. In this case, learning the terms that were mentioned the most, as well as the degree of positive or negative reactions to each term was the desired outcome of such knowledge extraction. Knowledge acquisition however does not always need a limited set of predefined experts. In contrast Chklovski (2005) performed a study encouraging volunteer website visitors to assist with the compilation of conversational data from a given dataset. This knowledge acquisition required the ability to process natural language and therefore would not have been suitable for an automated process.
Tacit knowledge can also be gathered passively from observations of procedures as well as conversations. Mueller, Kethers, Alem, and Wilkinson (2006) observed and recorded a handover process as it was taking place in a hospital environment. Shift transitions require a transfer of information in order to properly inform the oncoming staff. This handover process was intended to ensure that the staff would have adequate information to handle outstanding cases in the following shift. Most traditional handover processes involve explicit information in the form of patient data. Mueller et al. proposed a method of analyzing tacit knowledge and intuition that remains outside fixed documentation. Collecting data was found to be a challenge due to the nature of intuition and tacit knowledge. The handover process provided a first-hand account of the process. Interviews and questionnaires were then used to actively gather feelings from the staff about the handover process. Finally a follow-around process was used to directly observer entire shifts to form a connection between the shift and the handover process that preceded it. The results of the test provided evidence that the staff found intuition to be a leading factor in the comfort level of their shift. Key suggestions from the staff included a need for visualization as well as a way to retrace the steps taken in the previous shift.
Yoshinori et al. (2007) in contrast analyzed a conversation in order to improve the gathered knowledge. The process began with two experts detailing their knowledge of a given concept then analyzed and collected this information. After the information was collated, flaws were found and redirected back to the experts. At this point, the experts were able to correct or explain any flaws and then resubmit them back to the system. This process may repeat until flaws disappear or become minimal. Flaws in this context were defined as contradictions, lack of conditions, or lack of rules. Testing this process on fishing experts, the researchers found that the knowledge improved. Knowledge in a test environment was not as receptive to the process, as the researchers found the system was better suited to real-world examples.
Real-world situations may involve gathering knowledge from local populations. These groups of people possess experiences that can be beneficial to visitors wishing to increase their knowledge. Bilandzic, Foth, and Luca (2008) targeted a city environment. The focus of their study was to determine if visitors and new residents would benefit from a mobile system that would access a resident created knowledge base. The knowledge base was divided into two forms: direct and indirect. Direct methods would utilize the first hand knowledge of a local representative via phone or text message, while indirect knowledge came in a form of tags related to landmarks. After the study concluded, most participants found the direct methods more comprehensive, but the indirect methods were more practical. This is due in part by the ability to collect knowledge on one’s own time and the desire to not inconvenience another human. Mwebesa, Baryamureeba, and Williams (2007) proposed a similar system to learn cultural knowledge, but rather than a city setting, they concentrate on indigenous knowledge in developing countries. They identified indigenous knowledge as playing a key role in sustaining primitive societies, but theorized that the society would only advance if this knowledge was properly captured in a more permanent form.
While passive knowledge extraction may work in some situations, social networking sites have been proposed in order to allow users to contribute knowledge in a more familiar setting (Costa, Oliveira, Silva, & Meira, 2008). Specific applications such as blogs have been proposed by Huh et al. (2007) to manage corporate knowledge, while Su, Wilensky, Redmiles, and Mark (2007) have suggested that forums may provide a more structural foundation. Social networks have been found to help with collaboration among peers. These social networks benefit from focusing on both tacit and explicit sources. As relationships are built through the tool, knowledge is shared in a way that would be difficult to formally document (Costa, et al., 2008).
Huh et al. (2007) reported on the implementations of internal corporate blogs. While most blogs appeared in a public setting, internal implementations were being researched. A random selection of blog users using IBM’s BlogCentral application were interviewed to determine what types of knowledge sharing works best in this type of medium. Users were asked what type of content they reported as well as what their intended audience was. Content was divided into personal stories, open discussion, and information sharing. Audience was divided into no target, specific, and broad. After the analysis, personal stories and discussion was primarily targeted toward specific and broad audiences. However the knowledge sharing was equally spread amongst the audience levels.
Although considered part of the social networking framework, forums serve a different purpose. Su et al. (2007) targeted an implementation of a forum within the aerospace industry. Due to the need for collaboration on complex designs, the forum was created to allow open discussion and knowledge sharing. The authors found that this form of communication was most beneficial when constrained to a single source. This allowed the user community to concentrate on just the ideas that would benefit the group as a whole. In an educational environment, social networking takes on different aspects, but with a similar goal. Firpo, Kasemvilas, Ractham, and Zhang (2009) described a situation where commuting students lack the social aspects that resident students have. Social networking helped alleviate this concern by placing students on an equal level. Lack of personal contact usually results in a lack of knowledge sharing. However with virtual implementations, the authors found that they were able to replicate some of the benefits of face-to-face communication. One drawback encountered throughout the study was lack of participation. While the framework is considered beneficial, it becomes of little use if few participate. In this study, administrators had to play a prominent role in keeping the site active. By updating the portal often, students were encouraged to remain involved. Despite the concerns with participation, the students and faculty found the knowledge sharing among commuters to be greater online than if the students returned home immediately after class and had no face-to-face communication.
In addition to finding and collecting tactic sources, there are issues with maintenance. Large volumes present difficulties if resources are not equipped to handle the load. According to Song, Nerur, and Teng (2008) and Otsuki and Okada (2009) managing and storing these knowledge assets have a direct correlation to an organization’s success. Song et al. analyzed the transmission of knowledge by means of networked knowledge units. Through an empirical study, they found that nodes linking major portions of the network formed a bottleneck in some aspects but also provided associations that would otherwise have not been made. Otsuki and Okada proposed a knowledge support tool to specifically target newly created tacit knowledge. This tool attempted to find relationships between data and then extracting tacit knowledge from these sources. The process built upon traditional 3C analysis in order to first define basic characteristics. Users then used their expertise to map characteristics into meaningful relationships. The relationships formed connections between the nodes facilitating knowledge transfer.
Large volumes may also result from the active process of gathering tacit knowledge into a more explicit format. As the baby-boomer generation begins retiring, organizations are taking an active position towards trying to retain their expertise and experience. Delen and Al-Hawamdeh (2009) described a framework that is designed to form a knowledge management process. This process moved away from keyword based indexing as the authors found this an outdated and insufficient method. Through the use of web-crawlers and data mining utilities, small data pieces were compiled, forming a local knowledge repository. An intelligent broker module facilitated the communication from the user and allowed them to access the system from a single point of entry rather than searching each of the many repositories. Once the facilitation of knowledge had been improved, Delen and Al-Hawamdeh noted that this knowledge should be efficiently used while ensuring there is minimal loss. Knowledge re-use was an important factor especially when faced with situations such as retirement or department reorganization. This re-use of knowledge was evident in the proposed system when queries were submitted by a user. Before a query was run against the repository, previous queries and answers were referenced in an attempt to provide a more relevant and timely response. The repository could still be accessed, but was used as a secondary resource. All repository use would then be stored for later queries in order to strengthen the knowledge base.
Tactic knowledge utilization becomes essential when working within academic environments. E-learning applications can enhance knowledge management through the collaboration of a team in anticipation of performing a relevant task. This collaboration may take place between an instructor and students or across great distances. In order to assist with the process, learning objectives are created to provide specific goals and requirements. These learning objectives possess the ability to be distributed and applied to differing lesson plans. The primary benefit is the availability of the goals and instructions, so the learning process is not hindered by traditional barriers such as time or the need for real-time personal instruction (Yordanova, 2007). Learning processes share many characteristics with knowledge management, but context is a key component. Context can be added to traditional knowledge management systems in order to promote coordination among peers. Cabitza and Simone (2009) described context sensitive implementations within hospital environments. A simplistic example would be the casual annotation beside more formal printed documents. To the creator, these inscriptions added value to the original text, but are heavily dependent on the context. Without the original text, the meaning would be lost or misinterpreted. This specific knowledge is made more important in high risk fields due to the need for the context to be explicitly clear. Without understanding the connection between the annotation and source material, the additions may have been seen as erroneous. Certain medical conditions would necessitate an alternate approach if combined with another complication. If the context was not interpreted correctly, the possibility of a misjudgment may occur. The authors concluded that the need for flexibility must exist in order to complement the pre-defined documentation within the organization.
Context can also be applied to more casual domains such as social networking. Tagging helps unify diverse domains that otherwise may not have been easily bridged. White and Lutters (2007) analyzed the utilization of tagging in a knowledge management domain. Tagging eliminated the need for a top-down hierarchy; instead moving everything to a single flat level. After interviewing participants in the study, the authors found that 85% preferred a flat level and saw no need to organize the data in another method. The authors theorized that search engines have reduced the need for folders and trees, as they were seen as largely arbitrary to most of the participants. So rather than trying to categorize data into folders, tags could be applied as needed. These tags prevented the need to adhere to an organizational scheme, and in turn tied together heterogeneous repositories.
While knowledge in an organization could prove to be beneficial, it does require dedicated people to fully utilize it. The roles of knowledge workers were analyzed by Shen (2008) in order to define the core characteristics. Knowledge workers are not full time jobs, but are often incorporated into many facets of the modern workplace. Extracting and working with knowledge has become commonplace for work related activities, and includes acquisition, generation, coordination and assessment. The question posed by the researchers asked how the workers receive compensation for this increase in responsibility. The hypothesis tested to see if the wages have a direct relationship with employees involved with knowledge management. Shen determined that wages did increase, and were more productive in knowledge generation procedures over more generic knowledge work.
Data Extraction from Handwritten Sources
Text-based data mining has been found to be an important component of organizational repositories. However, the drawback to targeting informal text originates from difficulty with both transcription and interpretation. If a document is a hard copy, the process of converting the text into machine-readable text is the first obstacle, and one that is continuing to be solved as technology improves (Carenini, et al., 2005).
Optical character recognition has been used to convert printed text back into a digital format. This necessity may be due to lack of the original digital version or to age as many documents pre-date common word processors. As repositories began to populate with text-based sources, there was a need to ensure that the OCR process is accurate. However the large size of book or manuscript text may reach into the millions of characters, so error checking this length proved to be a difficult task. In one example, rather than attempting to compare the entire text Feng and Manmatha (2006) broke the structure down into smaller hierarchal parts. This process was performed in a way that did not require knowing the original structure, but instead dynamically partitioned the volume into manageable sections. The researchers found that by formulating a listing of known words, the OCR errors could reach upwards of five to eight percent and still produce valid output. Borbinha, Gil, Pedrosa, and Penas (2006) encountered a similar problem with a large recorded datasets. These sets utilized a server side master repository in order to achieve OCR error checking and consistency, while performing dynamic partitioning for lower bandwidth requirements.
Should OCR transcribed documents remain in a degraded state, retrieval methods are often difficult to achieve with satisfactory results. Magdy and Darwish (2008) assessed the retrieval rate of poorly interpreted text based on weighted selections. The authors found that a reduction in indexing overhead could drop over 95% while only incurring a 20% drop in effective retrieval rate. They found that full text searches on entire book contents were inefficient, and certain portions such as headers and titles could be emphasized with similar results. The addition of a Table of Contents also increased performance since it provided a reference to the entire document’s sections.
Overcoming noisy OCR results when the entirety of a document is required was a process researched by Stamatopoulos, Louloudis, and Gatos (2009). In order to analyze the contents of transcribed text, the contents were segmented into pieces using thresholds that target first at the sentence level, then phrase, word, and finally by character. Each recursive pass strengthened the recognition pattern until satisfactory results were achieved. In their evaluative study, a book from 1788 consisting of 94 pages was chosen. Using the recursive segmentation model, the accuracy rate was above 90% for character recognition, and above 95% for words and lines. Overall this was found to be a success.
Databases pose another issue for degraded OCR text. These become a greater issue when using transcribed text in relational tables as the primary key values may be interpreted incorrectly and in turn break the connection to the foreign key. In a study by Onkov (2009) historical documents had a limited number of possible key values. The finite list allowed the researchers to assign numerical values to each of the transcribed words, so that the returning text could be matched with the closest similar entry and then standardized within the relational database structure. Non-key values also benefited from lists of known values, and helped complete the relationships from the source files. This method required much prior knowledge, but with minimal user intervention the process was much more efficient than manual transcription.
OCR can be further improved through context clues. Yeh and Katz (2009) concentrated less on achieving exact OCR matches, but rather using the best results to identify regions of interest in order to quickly locate a relevant portion of a document. Of interest is the text associated with screen captures. While standard text in a manual may be digitized, screen captures were often saved in an image format made from pixels rather than text. By using over 100 manuals from common applications, Yeh and Katz were able to extract over 75,000 screenshots. By comparing sample dialogue boxes from online tutorials, the authors estimated a 70% accuracy rate of retrieving relevant documentation. Since the corpus and test set were not inherently related, they found this to be a good success rate. Additionally multiple OCR engines could be combined as Lund and Ringger (2009) demonstrated in their study. By using the strengths of three sample engines, error rates were reduced by over 50%. Efficiency also was improved with node-based heuristics with a reduction of node traversing by 35%.By increasing the efficiency and accuracy of OCR, most paper documents are able to be transcribed into a digital format.
Since handwriting is less structured than printed text, data acquisition is more difficult. There are issues with inconsistency between different users, single users and often with legibility. Rath, Manmatha and Lavrenko (2004) developed a method for archiving written manuscripts in a museum environment. They noted that there is a large quantity of historical manuscripts of great importance and value, but they did not have an efficient means to be accessed. Since many were too valuable to be handled and consumed too much data to be scanned and archived, little had been done to extract the data. In order to be more valuable, the text needed to be converted from handwriting to ASCII text. The authors acknowledge that the state of technology was currently lacking in regards to interpreting written text and that there was an inherent lack of current options. Instead their process involved using training examples based on known documents that had been transcribed manually. These examples were then compared to documents that had not been transcribed.
For the experiment performed by Rath et al., a sample of one document was used as a test against the remaining pages. Of an estimated 1000 pages, one-tenth was used as a training set. No attempt was made to read the text letter by letter, but rather to compare similarities in the writing, which in most cases would result in the same word or phrase. The process of analyzing whole words was chosen due to the nature of handwriting. Since cursive writing blends letters together, it is much more difficult to break each down and interpret them into plain text character by character. Although at some point, converting writing to text will be important, their approach matches visual clues to complete words in order to build a keyword driven approach to the mapping. A comparison between a scanned word and typed transcription will provide the link between the two, further allowing other sections of the manuscripts to be understood and indexed. The purpose of the experiment at this point in time is not to interpret the text, but rather to formulate a feasible method of retrieval similar to Yeh and Katz’s (2009) work with typed text OCR.
In a follow-up paper by Howe, Rath, and Manmatha (2005), data gathered from samples was used to formulate a system using a decision tree technique to increase the performance of the information retrieval. By using their model, text from a sample set of only 20 pages reached accuracy levels of the previous 100 used for testing. Words that shared similarities with other words were candidates for an expedited retrieval process, since they could be narrowed down from pre-classified groups rather than scanning for all examples. In other cases, words may have been scaled to fit a standardized baseline and length in order to eliminate variance in the analyzed image. When standardized to size, decision trees then formulated word suggestions based on sample pixels. If a pixel matched a solution, other adjacent pixels were checked and the resulting choices were narrowed. It was noted by the authors that a perfect decision tree would be detrimental to the accuracy and efficiency of the system, since in addition to being labor intensive, this approach would be more restrictive and often not find an exact match. The purpose of the boosted decision trees is to not attempt to find an exact match, but to heuristically determine the best match and achieve low error rates. The issue of importance noted by Howe, Rath, and Manmatha concentrated within the technology used. They noted that the techniques were neither entirely new nor designed for this data type, but still provided satisfactory results in this new domain of hand writing classification.
Improving accuracy is still a goal however if the end result moves beyond simple retrieval. Mane and Ragha (2009) concentrated on individual character recognition, a goal which they clearly stated is a difficult one since vocabulary context is important even in human assisted transcription. Character recognition in this study was achieved through analysis of the elasticity and deformations of handwritten examples with known samples. A series of steps prepared the characters by reducing colors to black and white, trimming excess blank space from the edges, and conforming to a standard canvas size. Feature extraction is then possible with the cleaned image, and through a process of stretching the image, comparisons could be made to sample sets. In these cases, training data was an important component.
In other cases, extraneous markings on the physical paper could add additional barriers to successful handwriting recognition. Reports filled out by hand sometimes consisted of boxes used as containers for data. Often due to lack of space, the contents touched the sides or letters overlapped in order to fit the entire words or words. Neves, Carvalho, Facon, and Bortolozzi (2007) and You, Shi, Govindaraju, and Blatt (2009) discussed the difficulties associated with transcribing text from formatting containing design elements. Neves et al. proposed methods to identify corners of table elements. By using common line intersection definitions, cell content extraction was possible.
Identification alone was not found to be sufficient however. At times the text overlapped the design elements and was removed with the table lines. You, Shi, Govindaraju, and Blatt (2009) worked with automated interpretation of police accident reports, which face additional illegibility concerns due to the nature of accident scenarios and their inherent time constraints. The primary purpose of the authors work was to remove formatting lines so that text could be separated and later interpreted. Identifying lines was not found to be a difficult procedure, however simply subtracting them from the image left gaps in the text if the strokes overlaid the pre-existing lines. This problem was solved by taking into account the height of the line by implementing a vertical consideration to the existing horizontal pass. The line was only removed if sufficient white space existed above and below. From a sample of 100 reports, 70% accuracy was achieved with higher percentages theorized if additional cross-checking is used.
Much like during accident scenarios, people may resort to handwritten methods due to a need for convenient and time sensitive schedules. In the emergency room, handwritten notes are used to check in patients while they wait for treatment. While it is easy for the doctor to write down information by hand when attending to patients, it poses some difficulty when the time comes to transcribe this writing into the computer system. These notes may be illegible due to different writing styles or the need to jot down information quickly. Sometimes these forms often remain untouched until over a year after their creation. This lag in attention and user motivation demonstrates the associated problem with this form of documentation (Govindaraju, 2005).
A process of retrieving pre-care hospital reports has been outlined by Govindaraju and Cao (2007), and they detailed concerns within this specific environment. Formatting is often different for every doctor, and the terminology used in the medical field does not usually appear in common dictionaries. Unassisted handwriting recognition was estimated to have about a 30% accuracy level; however the authors propose a method to increase that amount by providing a finite number of probable text matches. A follow-up paper by Govindaraju, Cao, and Bhardwaj (2009) proposed an image-based method for handwritten transcription. Rather than interpreting the text, features were identified and matched. With a sufficiently comprehensive dictionary, specific matches could be made even for complex medical terminology.
The importance of creating training sets and example data has been discussed, but these tools must initially be created. This is often performed manually and required a laborious process of matching scanned images with their digitized counterparts. However Kaiser (2005) stated that building a computerized vocabulary could be achieved though input such as verbal dictation or handwritten gestures. His research attempted to combine both gestures and verbal confirmation to enhance the vocabulary input process. By using both methods in parallel, the error rate was reduced due to the redundancy. The process was ultimately designed to place most of the work on the system rather than the user. Wang, Li, Ao, Wang, and Dai (2006) found that while handwriting errors were generally less than verbal errors, there were cases where the pronunciation generated a stronger match than the interpreted gesture. During their study the overall the combination of both methods produced over a 50% decrease in errors compared to verbal input alone, and a seven percent decrease in gesture input alone.
In addition to creating training data, dynamic gesture input can be used to learn a user’s handwriting style and make transcription much easier. Kienzle and Chellapilla (2006) developed a gesture recognition program that orients towards specific users. Since every person writes differently, a computer transcription program was best suited if that adaptation is taken into consideration. Like many procedures, training data was required by the prospective users in order to provide the computer with samples to analyze. There was an inevitable tradeoff between generalization and user specificity, but the authors found that increased accuracy was a preferable trait.
Using a similar method, Shilman, Tan and Simard (2006) continually improved their system using provided test data, but did not restrict the training set to one specific user. This test data was combined with heuristics that analyzed the context of the writing and tried to intelligently determine the most likely candidate for what was written. This system also allowed users better options when choosing the correct words if the system was unable to completely understand the gesture.
Summary
The review of the literature revealed descriptive case studies and experiments that covered topics relevant to this study. The aging workforce was found to be a concern among many researchers, and proactive solutions were considered the most appropriate. As Hafida (2008) noted, workplace knowledge was important to an organization and must be captured while the individuals who possess the knowledge were still present. Experts played a critical role, since they were primarily the originators of knowledge creation as well as those who are best suited for knowledge extraction.
In order to properly capture expert knowledge, repositories were researched for their effectiveness. Repositories were found to be useful in two contexts; first for locations to actively contribute information, and secondly as a place where information may already exist and can be utilized. While large databases and the World Wide Web were suitable and efficient sources as noted by researchers such as Baillie et al. (2006) and Banerjee (2008), paper based document repositories were often overlooked. Norrie et al. (2005) commented that paper will most likely never be replaced entirely by digital counterparts. To allow for this, Norrie proposed appending features to traditional paper in order to achieve digital synchronization. Others such as Steimle (2009) described methods to use paper as a proxy rather than a direct link.
Tactic knowledge was also investigated as it forms the source for many expert extraction processes. Processes such as those described by Carenini et al. (2005) involved following predefined experts in the field and gathering useful information through observation. Rather than looking to gather information in future observations, past texts were also found to be beneficial sources. Handwritten text often contained notations that formally typed text would not possess. Since the source is directly from a user, mining for information yielded personal insights and knowledge as noted by Govindaraju et al. (2009). For this study, handwritten text will be specifically analyzed for expert opinion and determination of value for the repository will be studied. The literature review covers these aspects and provides a foundation for the research.
Chapter 3
The goal of this study was to determine the value of handwritten information found within work orders. In order to define the value of the information, the researcher utilized a known group assessment technique to systematically process and analyze the written text as part of an evaluative study. The research addressed two primary research questions.
The first research question was: How can the value of handwritten data from a specific collection of documents be determined in a manner that is scalable and repeatable? The second research question was: To what extent is the handwritten information from the collection of documents a valuable source for knowledge acquisition? These questions were used to form the basis towards providing validation that the work orders contained value by building a scalable and repeatable testing methodology. It was important to not only form the testing procedure, but also to ensure that the process could be generalized to a similar document repository.
To strengthen the study and ensure scalability and repeatability, the study was performed on two repositories from the same department and by the same expert panel. The results from this second implementation were compared to the initial results using a quantitative test of value as well as a qualitative survey tool in order to validate the consistency (Ott, 1992; Thomson, Saunders, & Foyster, 2001).
Step 1: Selecting Expert Panel Members
The researcher began the study by meeting with the manager and his staff, and they provided permission to use their location as the site of the study. Their permission letter can be found in Appendix A. The researcher gathered a basic understanding of some of the daily tasks in order to better comprehend typical procedures. Since experts played a prominent role in this study the researcher, with the help of the manager, identified employees suitable for judging the work order content. Aggarwal et al. (2005) and Goldman et al. (2008) proposed that experts should have been selected from those who have daily experience as field technicians, and whom a manager recommended based on personal experience. The manager was asked to form a group of experts who would form the expert panel. The panel consisted of 20 experts based on the suggestion by Clayton (1997) that 15 to 30 participants would be sufficient in order to ensure the quality of assessment. Due to the small size of the organization, communication was performed internally through the manager for the purpose of coordinating the study.
Step 2: Choosing and Organizing a Repository
With the assistance of the manager, repositories containing work orders were identified. The repository content did not play a key role in the selection process, as the only required attribute was the inclusion of a handwritten comment section that provided supplemental information (Carenini, et al., 2005). The researcher performed an initial assessment of the repositories in order to select a suitable collection for the study. The two repositories contained 100 and 123 valid documents respectively in order to ensure a normalized distribution (Ott, 1992).
Valid documents in this context were work orders that contained freeform comments beyond simple statements. As Bondarenko and Janssen (2005) stated, only documents with some level of expert insight are beneficial for the study. Content area expertise was not needed to eliminate unsuitable work orders, since they were either blank or explicitly stated that nothing of importance occurred, thus the researcher was able to assist in the process of excluding these invalid entries from the analyzed repository. Since this research question was answered in part by performing and comparing two assessments, this selection process was performed on each of the two identified repositories (Liu & Fidel, 2007).
Before the experts could analyze the work order comments, they assisted with the development of an assessment rubric. This study utilized an expert panel following the Delphi Group Technique to develop and validate the rubric and then use this rubric to assess the work orders. The Delphi consisted of three primary phases: rubric and metric creation, initial work order assessment, and secondary assessment. The rubric and metrics were used on both assessments.
The rubric contained indicators of value pertaining to the work order comments specific to the repository topic. During the initial step in the group technique, the expert panel suggested relevant indicators of value. This is based on the assumption that they had the necessary expertise to identify key areas of importance. Like all aspects of this implementation of the Delphi, the expert panel submitted suggestions anonymously.
The researcher collected submissions from each expert and formed a preliminary list of value indicators. Based on the recommendations by Linstone and Turoff (2002) and Goldman et al. (2008) only one round was found to be sufficient to gather suggestions. In order to form the final set, this study followed the proposal by Goldman et al. and only retained indicators suggested by two or more experts while duplicate suggestions were combined. The final suggestions were: Potential cost for repair or maintenance, Man-hours/Labor, Environmental Concerns, and Outfall Condition. This final set then became the rubric for the remainder of the Delphi. An example of the initial rubric is included as Appendix B.
The rubric was used by the researcher to rate the key areas that helped determine the value of a work order comment. At the end of the Delphi, each value-indicator assisted the researcher in determining if the resulting consensus provided evidence of the repository’s overall value. These indicators were also used to compare the statistical difference between each of the two analyzed repositories for the purpose of determining the scalability of the instrument (Ott, 1992). These processes are further defined in Step 8.
In order to determine the overall value of the repository, the experts identified metrics defining how the rubric would directly relate to value and determined what factors would attribute towards making the process ultimately worthwhile. The metric definitions enhanced the previously defined rubric in order to use the value-indicators and create a wider assessment of value. The definitions possessed a degree of variability due to expert opinion, but quantified the value-indicators for each rubric item as well as the associated rating scale. The goal in defining the metric definition was to determine how the repository as a whole would be assessed as valuable.
As a continuation of the rubric creation, each expert received the rubric finalized in Step 3 from the researcher and anonymously suggested a definition detailing how the rubric ratings would designate value for the repository. As with the rubric suggestions, this study followed Goldman et al.’s (2008) proposal to consider only suggestions stated by two or more experts. Based on Linstone and Turoff’s (2002) case study, the expert panel was asked to choose the definition that they found most suitable to define value.
Two main considerations were proposed by the panel to judge overall value. The first was an overall minimum grand mean that averaged the means across the value indicators within the rubric. The other suggestion was to calculate a percentage of individual ratings above a given value. The consensus by the expert panel was that a percentage of minimum rating values would be used to calculate the final values of the ratings. The thought process was that the ratings on the lower end of the scale were not deemed as important. While these low ratings would result in inefficient use of time, the primary focus was on finding comments at least reaching a minimum amount. A grand mean would require a collection of higher rating for each lower extreme, while a percentage of minimum values would not factor in the degree of value, but rather pool the ratings into two groups.
Among the experts who suggested using a percentage of minimum values, the majority determined that half of the ratings must exceed a value of ‘four’ in order to consider the entire repository to be valuable. At this point, the first section of the Delphi was complete, and the expert panel was ready to proceed to the work order assessment phase.
Step 5: Transcription of Work Orders
After the appropriate repository had been selected, and the rubric scale had been finalized, the researcher transcribed the contents of the work order comments into a spreadsheet. This manual transcription simulated the automated procedures that will someday assist with the difficulties surrounding handwritten interpretation (Callan, et al., 2002). In addition to the work order comment, the spreadsheet contained a rating input field that was later filled in by the individual expert during the Delphi process. The rating field was based on a zero to ten scale as dictated by Goldman et al. (2008).
Step 6: Rating Work Order Comments
The comments included on the work orders were evaluated by the expert panel as they continued the Delphi process. The implementation of the process was comprised of three parts: initial assessment, revision, and additional consensus procedures. Assessment and revision processes were outlined in Goldman et al.’s (2008) study, while the consensus determination was based on Linstone and Turoff’s (2002) core methodologies and techniques. Goldman et al.’s study provided the basis for the recursive process from which the experts performed their assessments and built upon the panel’s collective opinions. Linstone and Turoff provided core Delphi techniques that were applicable to determining if consensus has been reached. The combination of the two studies formed the processes required for this implementation.
The revision process was comprised of at least one round past the initial assessment but was repeated if an adequate consensus was not reached. Each step used the previous findings to strengthen the assessment and move towards a consensus. The spreadsheet allowed the expert panel to quickly progress through the entries by reading the comments then recording their assessment. Since the Delphi was designed for experts to work independently, the spreadsheets were distributed and collected individually.
Step 6-A: Initial Rating. In the first step, the researcher provided the expert panel with the spreadsheet. At this time only the work order comment field and the corresponding rubric input fields were present. Each expert began at the first record and, after reading the work order comment, recorded the rating for each of the value-indicators before moving to the next record. This process continued until each record had been read and rated.
Each expert provided the researcher a completed spreadsheet. The researcher took these spreadsheets and collected the ratings for each record. At this step the only input provided from the experts was numerical, so the average was calculated from each corresponding rating. The work order comment and rating pair then formed the baseline for the following revision step.
Step 6-B: Revisional Ratings. The next step began the revision process. This step was repeated until a consensus had been reached per the requirements detailed in Step 6-C. The spreadsheets were returned by the researcher to the expert panel with the rating averages presented for reference. The previous rating input field was cleared allowing for a revised rating. Experts used the averaged rating as a guide and influence for a new rating. An example of the revised rubric can be found in Appendix C.
Additionally, the researcher added a field that displayed the inner quartiles of the previous ratings, which was known as the local consensus range. While the expert panel’s ratings should have been influenced by the results of the previous averages, they were free to disagree and rate outside this range provided they had a reason. Using this range as a guide, each expert was required to describe his or her reasoning for any rating that fell outside these values.
This process allowed an expert to explain why his or her rating is justified and avoid a possibly inaccurate overall rating average. Thomson et al. (2001) advised that there may be cases where one expert is more knowledgeable in a certain area and can correct a collective misunderstanding. While the recursive rating steps were designed to move towards a consensus, re-rating the work order comment without the ability to provide comments might have created a situation where experts simply agreed without proper reasoning or to follow the trend (Goldman, et al., 2008; Linstone & Turoff, 2002).
The spreadsheets were returned to the researcher and processed in a similar manner as the initial ratings. In addition to averaging the ratings for each value-indicator, the text fields containing reasoning for any rating outside the acceptable range were combined.
Step 6-C: Determining Consensus. After each revision step, the process was tested for consensus. While Goldman et al. (2008) declared consensus after the three rounds (initial rating and two revisions) of the Delphi, this study withheld a declaration until a minimum threshold is met as defined in Linstone and Turoff’s (2002) techniques and applications of the Delphi process.
Linstone and Turoff (2002) described through their case studies that a constant state of rating oscillation or ‘noise’ exists between revisions even after genuine opinion shifts have ended. This noise historically averaged to a change level of about 13%, with 15% being the maximum value to establish stability. A change level was calculated by first finding the sum of the absolute values of the difference between the current mean rating and the mean of the previous revision for each sample, in this case the work order comment rating. The sum was divided in half, and then divided by the number of experts participating in the group technique.
Let X1, X2,…,Xn be n observations of the difference between the current mean rating and the mean rating of the previous revision for each work order assessment. The change level was calculated by the formula below and converted from decimal to a percentage value.
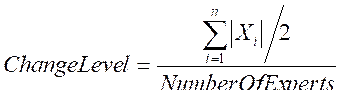
Each revision in the Delphi was processed for a change level value based on the previous assessment. When the change level was less than 15%, the ratings were considered to have reached a normal level of oscillation and a consensus was declared. When after a revision the change level was 15% or higher, consensus was not considered to be achieved, and the process was repeated and retested. Once consensus had been achieved, a grand mean was used for the final analysis as defined in Step 8.
After completion of the prototype system, the expert panel assessed a second repository using the rubric from the initial implementation. The repository topic remained within the same department and followed the same steps of the Delphi as outlined for the initial implementation. This allowed the researcher to compare the results of both implementations and attempt to answer the research question focused on repeatability and scalability.
Completion of the Delphi provided the raw data needed for both research questions. The final results were summarized and converted to a spreadsheet in order to provide only the data relevant to the researcher during the analysis phase. Since the Delphi was designed to form a common consensus, the final averages should have represented the collective opinions of the expert panel (Fowles, 1978; Goldman, et al., 2008).
First a quantitative test was used to compare the two implementations through the use of a t-test. The researcher calculated the grand mean for each implementation of the values given to each work order comment, and since the goal of the study is to find the overall value, this averaged out individual value indicator ratings that may differ between the prototype and second implementation. The grand mean was calculated by first taking the averaged values of the final ratings after consensus has been reached. For each value-indicator in the rubric, the final ratings were averaged for that indicator. Finally the average of all indicator values comprised the grand mean.(Yesilada, Brajnik, & Harper, 2009)
There should have not been a statistically significant difference in the overall value of work order comments between the two repositories as measured by the grand mean (Ott, 1992). For a confidence level of p < .01, the null hypothesis for mean μ1 of the prototype system and mean μ2 of the second implementation was:
H0 : μ1 - μ2 = 0
The alternate hypothesis was:
Ha : μ1 - μ2 ≠ 0
Step 9: Qualitative Analysis – Survey Preparation
Additionally, a qualitative measure was used to gather expert opinion on the process. This process consisted of a survey designed and validated by Thomson et al. (2001) and based on core validity measures described by Nitko (1996). Thomson’s survey addressed common concerns such as identifying possible additions or omissions as well as confirming assessment consistency, cost effectiveness, timing, and generalization between experts. The survey questions created by Thomson were applicable to any implementation of an assessment instrument and were used without modification. However, the researcher appended notations to each question providing the experts more clarification as to how the question would pertain to this specific study. Some notations also clarified the specific meaning of the questions for members of the expert panel that may not understand technical research terminology. The survey questions can be found in Appendix D. Permission to use the survey can be found in Appendix E.
Nitko’s research provided evidence towards the validity and generalization of assessment instruments such as the rubric described and used in this study. Eight forms of assessment evidence were described including content, coherence, consistency, stability, substance, practicality, generalizability, and consequences. Since the survey created by Thomson et al. (2001) was based around these validations, each question or questions addressed a specific concept. A correlation between the survey questions and Nitko’s listing of validity evidence can be found in Appendix F.
The data gathered from the survey combined with the validation evidence addressed the first research question. The researcher validated the scalability and repeatability by analyzing each form of evidence and their relation to the experts’ answers. While some answers were a simple yes or no, the more descriptive responses provided insight directly from the panel. Evidence such as consistency, stability, and generalizability helped strengthen the case that the entire process will be applicable when expanded.
The survey was distributed electronically by the researcher for each expert to fill out individually after both repositories had been analyzed. At this point, the expert panel was able to apply the survey questions to their experience using a single rubric to evaluate two repositories. Questions validated the usefulness of the process, but also provided evidence towards the repeatability of the assessment. While many of the survey questions asked for yes or no responses, the experts were encouraged to provide more detail if applicable. Descriptive comments helped provide the researcher with more content for analysis as well as validation for the assessment instrument.
Step 11: Survey Collection and Analysis
After the experts had completed the survey, the researcher collected the results and compiled the answers. Each form of evidence described by Nitko (1996) was addressed by a question or combination of questions from the survey. The analysis was descriptive in nature and required the researcher to compile the answers in a manner that demonstrated how the evidence enhances the validity of the instrument. The analysis then was presented individually for each validity concept.
Second Research Question
During the preparation phase, the experts had been asked to provide metrics that would indicate if the repository as a whole is worth analyzing. During Step 4 the metrics would have been finalized from the initial suggestions, and as Goldman et al. (2008) state, only suggestions offered by two or more experts were considered for the final set of metrics.
Repository value was ultimately determined by the expert suggested metrics, but as Brinkman and Love (2006) describe in their research, value was expected to be based upon either a grand mean above a designated level or a percentage of documents rated above a minimum value. The determination of value was processed by the metric specifications, and the repository was judged as worthy or unworthy of transcription. This determination factored into future decisions to transcribe and analyze other repositories beyond the study.
The study took place within a local town public works department since that group had expressed interest in the study. This organization is responsible for overseeing town utilities as well as performing preventative maintenance. The department is headed by one manager, a sub-manager and 19 field technicians. There is a central office where equipment and vehicles are stored, however most daily work is performed in the field. Tasks and outstanding issues are currently managed using a local Access database by the lead manager using input from the employees. This database only holds active jobs and does not factor in comments or observations that do not directly affect a task. For each task however, work orders are printed and filled out by hand. Based on the job scope, these work orders are collected in a binder at the end of the task or period. The binders are placed on a shelf or in a filing cabinet and are not referenced after this point.
The study utilized the assistance of the town public works manager. It was in management’s best interest to pursue completion of this project as it benefited their current procedures and hopefully laid the groundwork for a more efficient system in the future. In addition to the management layer, the researcher worked with the employees in order to utilize their expertise and form the expert panel. There are approximately 1,000 paper documents distributed across several systems that have been saved under the assumption that they contain important information. This belief has prevented the disposal of such resources and provided a rich basis for gathering the data needed to perform this research exploration.
Computation of the statistics and compilation of the spreadsheet was performed on a standard desktop computer, as it did not require labor-intensive processes beyond that of a personal computer. Software included Microsoft Office applications such as Excel for spreadsheet requirements and reporting analysis. The expert panel created tools such as the rubric for a prototype system during the first phase of the study. The prototype system then formed the structure for a second implementation in order to validate the process. Communication with the organization was transmitted through e-mail and phone correspondence as well as face-to-face meetings as needed.
The processes and methodologies in this study were based soundly in the literature. The primary model used was the Delphi process. Most of the implementation followed the steps outlined by Goldman et al. (2008), as it is based upon the three core components of the Delphi. In instances where Goldman’s process did not adequately fulfill the needs of this study, Linstone and Turoff’s (2002) fundamental techniques and applications were referenced as they have described in detail many uses of this technique with case studies proving its effectiveness.
In order to assess the usability of this study’s instrument, the researcher utilized a survey tool to gather expert opinion. This tool was based on the questions compiled and validated by Thomson et al. (2001). The survey was created specifically to validate expert assessment, and was based on core validity principles and evidence described by Nitko (1996). Validation for the survey was performed by expert panels during case studies with several large corporations such as Woolworths and McDonald’s. By using the evidence of assessment, the authors were able to complete a descriptive analysis of the instrument.
Chapter 4
This chapter contains the steps taken in detail, which were used to produce the final results in this study. When applicable, steps described in the methodology chapter that were subject to change or required expert decision, will be presented with their outcomes. Additionally, some analysis was required during the primary assessment before obtaining the final results and this will also be detailed. The quantitative and qualitative results obtained in this study follow the data collection and will be summarized.
The researcher initially met with the public works manager to discuss the formation of the expert panel and to identify valid repositories. The manager produced two document collections for the consideration consisting of over 500 work orders each for the 2006 and 2007 calendar years. Both document sets have remained in storage since completion and have no alternative transcriptions. The work orders cover outfall inspections performed annually throughout the town. At the bottom of each is a blank field for technician comments relating to the structure of the outfall, cleanliness, obstructions, and potential concerns or work needed. Many documents stated that the outfall was clear and running, so the researcher was able to remove these documents from the rating procedure as dictated by the methodology. After invalid documents were removed from the collection, the two repositories for 2006 and 2007 resulted in 100 and 123 documents respectively.
Since the panel would form the basis of the study, it was critical to select the qualified members as early as possible. The manager identified 19 participants from the department who were active field workers in the organization in addition to his participation and the assistance of a sub-manager. All but one field technician were willing to become part of the expert panel since the work would be performed during business hours. Coffee was provided to compensate for their time, and management assured the group that this activity was officially approved.
Consent forms were handed out before any of the study procedures were conducted. The researcher briefly explained the time and effort requirements for the study and allowed the expert panel to read the consent form and ask questions. Once the consent forms were filled out, the researcher began the process of defining the rating rubric forming the first phase of the Delphi Group Technique. Each participant was asked to anonymously list items that would define value for a work order comment. They were also asked to propose the metrics needed to define overall value for the repository. Since this phase only required one round to be sufficient, the researcher collected the suggestions to conclude this session and the rating steps were planned for the following week.
The researcher manually transcribed the work order comments into a spreadsheet which was then used to form the final rubric. The value indicators suggested by the expert panel were analyzed and narrowed down to items occurring more than once. The final suggestions were: Potential cost for repair or maintenance, Man-hours/Labor, Environmental Concerns, and Outfall Condition. These four indicators were appended to the rubric, and blank rating fields were added for each work order comment. A sample page from the initial rubric is included as Appendix B.
A second meeting was initiated with the expert panel for the purpose of performing the initial rating and to procede with the next phase of the Delphi. The rubrics were handed out, and the experts were allowed to fill these out as time allowed. They were allowed three days to complete the rubrics, after which point the researcher checked on their status and determined if more time was needed. Some participants were able to complete the rubric the same day, while others had to wait until a lunch break due to their schedules. Once all of the rubrics were completed, the researcher collected them and was able to begin the initial processing.
Two copies of the spreadsheet were made in order to compile the data from the individual rubrics. The first copy extended the columns from each value indicator in order to provide space for all 20 responses, so in turn each rating could be easily averaged. The second copy expanded each value indicator to three columns: the average of the previous round’s ratings for that comment, a range comprised of the inner two quartiles, and a blank field for the next rating as described in the methodology. A sample page from the revisional rubric is included as Appendix C. While the first copy was used only by the researcher, the second became the rubric handed out to the expert panel for the next rating session. The initial aggregate averages on a 10 point scale are as follows:
Cost: 3.0 Man Hours: 3.2
Environment: 3.0 Condition: 3.5
Figure 1. Repository 1, Round 1 Averages
The researcher returned to the expert panel with the revised rubric. The panel was again asked to provide ratings for each of the work order comments, but to take the previous average into consideration. They were advised to use the averages only as guidance but if their rating was outside the inner quartile range for that comment, they were instructed to provide a reason. They were once again given three days to complete the rubrics before the researcher collected the spreadsheets.
As with the initial rating, two copies of the rubric were made. The 20 expert ratings were collected in the first, while the second copy calculated the new averages and inner quartile ranges. The results from round 2 are as follows:
Average Rating Outside Inner-quartiles
Cost: 3.2 70
Man Hours: 3.4 113
Environment: 3.1 19
Condition: 3.5 37
Figure 2. Repository 1, Round 2 Averages
The Delphi process requires at least two iterations, so after this round the researcher was able to test for consensus by comparing the set of averages from the previous to the current session. Consensus was tested individually per value indicator. This allowed further iterations, if needed, to be re-rating only on the indicators that did not reach consensus (Linstone & Turoff, 2002). The change levels from the initial to the second revisions are as follows:
Change Level Sum of Rating Differences
Cost: 47.0% 18.8
Man Hours: 48.2% 19.3
Environment: 24.2% 9.7
Condition: 27.1% 10.8
Figure 3. Change levels for Value Indicators on Repository 1, Round 2
No values from this round were less than 15%, so consensus was not reached, and a third round was required. The same process was repeated and the experts received a new rubric with the previous round’s averages and ranges. Round 3 results are as follows:
Average Rating Outside Inner-quartiles
Cost: 3.2 28
Man Hours: 3.4 35
Environment: 3.1 13
Condition: 3.5 48
Figure 4. Repository 1, Round 3 Averages
Once completed, the researcher collected the rubrics and calculated the new averages and change levels. These levels from the second to third round are as follows:
Change Level Sum of Rating Differences
Cost: 14.3% 5.7
Man Hours: 12.8% 5.1
Environment: 9.9% 3.9
Condition: 13.7% 5.5
Figure 5. Change levels for Value Indicators on Repository 1, Round 3
One of the value indicators in this repository was just under the maximum level of change, but all remained within the acceptable range. Once consensus had been reached on all four value indicators, the second repository underwent the same process. The original rubric was used to rate these comments, so the value indicators remained consistent. Initial values for the second repository are as follows:
Cost: 3.6 Man Hours: 3.8
Environment: 3.5 Condition: 3.9
Figure 6. Repository 2, Round 1 Averages
Sessions with the expert panel began with an initial rating and were followed by the first rating revision. Values for the second round are as follows:
Average Rating Outside Inner-quartiles
Cost: 3.8 93
Man Hours: 3.9 110
Environment: 3.6 20
Condition: 4.0 36
Figure 7. Repository 2, Round 2 Averages
After the revision round, change values were tested to determine if consensus had been reached. These values are as follows.
Change Level Sum of Rating Differences
Cost: 46.6% 18.6
Man Hours: 53.4% 21.4
Environment: 26.6% 10.6
Condition: 32.5% 13.0
Figure 8. Change levels for Value Indicators on Repository 2, Round 2
As with the first repository, two rounds were not sufficient, and consensus was not reached. The researcher created a new rubric and sent it back to the expert panel to re-rate the ratings again. The results are as follows:
Average Rating Outside Inner-quartiles
Cost: 3.8 15
Man Hours: 3.9 25
Environment: 3.5 22
Condition: 4.0 35
Figure 9. Repository 2, Round 3 Averages
The change values from the second to third round are as follows:
Change Level Sum of Rating Differences
Cost: 10.1% 4.0
Man Hours: 11.3% 4.5
Environment: 11.1% 4.4
Condition: 12.2% 4.9
Figure 10. Change levels for Value Indicators on Repository 2, Round 3
The change levels for this revision were under 15% for all value indicators, so consensus was considered to have been reached. During these final rounds, the experts began to agree with the previous average and carried the value over as their rating. Most averages changed only in the range of .1 to .2 points. Many of the less consequential comments did not change at all, which helped keep the change levels lower. With both repositories having reached consensus, the expert panel was able to move to the final stage.
The final requirement of the expert panel was to complete an assessment survey. The survey was presented only after the second repository was found to reach consensus on all four value indicators. After reaching consensus on the second document set, the Delphi process was considered complete, and the expert panel was able to reflect on the experience and procedures. The survey was handed out, and the researcher briefly explained some of the questions needing to be simplified into laymen’s terms. The researcher also requested that the participants provide more detailed answers to the questions rather than replying ‘yes’ or ‘no’ for all.
The expert panel was no longer needed after this point, and the remainder of the analysis was performed by the researcher. Utilizing the raw data, a quantitative and qualitative measure was used to answer the first research question relating to the repeatability of the study, and a quantitative metric was used to answer the second research question relating to the overall value and usefulness of the repository.
The researcher used a t-test to perform a quantitative test to determine the repeatability of the study based on a grand mean generated for each implementation of the Delphi process. The grand mean was formed by first finding the mean of all the final ratings for each value indicator, which in turn was the average of each comment rating across the expert panel. The mean for each value indicator was computed into a single grand mean forming the basis of comparison for the t-test. The results of the t-test are as follows
Repository 1: mean = 3.325 SD = 0.150
Repository 2: mean = 3.8 SD = 0.216
t = 3.6122 Degrees of Freedom = 6
Mean Difference = 0.475 (95% confidence interval: 0.153 to 0.797)
p = 0.0122
Figure 11. T-test for Work Order Repository Ratings
Due to the fact that p is greater than 0.01 as designated at the 99% confidence interval, the null hypothesis cannot be rejected and the repository means can be considered to have no statistically significant difference.
The final analysis dealt with the overall value of the repository data in order to answer the second research question. The expert panel was asked to provide metrics that would determine this value. The experts had decided that 50% of the ratings must have a rating of ‘four’ or above. The final ratings for the two repositories were used to determine this overall value. The percentages of ratings above the minimum value for each are as follows:
Repository 1
Cost Man-hours Environmental Condition
27% 33% 18% 36%
Overall: 29%
Repository 2
Cost Man-hours Environmental Condition
49% 56% 30% 50%
Overall: 46%
Combined: 37%
Figure 12. Metric Calculations for Overall Repository Value
The first repository’s score of 29% was below the required 50%. Environmental importance was found to be the lowest scoring value indicator, with the other rubric groups being about equal. The second repository displayed a similar relationship between the rating categories, but at an overall value closer to the required 50%. Since the t-test determined that the repositories were statistically similar, the values of the two repositories were averaged and resulted in a score of 37%.
In order to qualify the answers from the survey created by Thomson, et al. (2001), the researcher matched up questions with the eight forms of evidence that provide validation for the technique as proposed by Nitko (1996). Each form of validation will be discussed briefly followed by the results of the corresponding questions. An aggregate report of the results of this study is presented in Appendix G.
Representation of Evidence: The first form of evidence dealt with how the assessments represented the study. Question 1 asked if the assessments covered the entire range of content within the topic, of which 86% of the participants agreed that it did cover the topic adequately. Question 4 asked if the assessments consistently reflected actual work practice, and 73% agreed that this was the case. One participant who agreed added their comments “always try to assess worse case senerio[sic]”. Another participant who disagreed made the comment, “Not enough manpower to complet [sic]”. Questions 5 and 6 asked if any assessments could be added or omitted respectively. Sixty percent responded that some assessment could be added, and 27% responded that some could be omitted. Of those who agreed that some assessments could be added, their comments included concerns such as: a need for prioritization, more information within comments, assessment of level of detail within comments, and notations for organization and scheduling. Those who agreed that some assessments could be omitted did not provide any significant comments.
Internal Coherence: Question 8 dealt with the way assessments may be performed on two separate topics. If some overlap existed on more than one topic, would the assessments remain consistent if performed separately? Seventy percent agreed that the assessments would remain consistent.
External Consistency: The assessments were performed by an expert panel within the same organization from which the work orders originated. The external forms of evidence asked how the assessments would perform outside the organization with another group of participants. Question 9 asked if the study assessments would remain consistent if compared to other forms of job related assessment. Ninety-one percent agreed that they would remain consistent. Question 10 asked if the outcomes of the assessments would be beneficial to outside parties that reviewed the data. Sixty percent responded that it would. One participant added that, “they would need to kow[sic] where the problem lays per comment”, indicating that additional information would still be needed for others to fully understand the assessments. Question 11 asked if the assessments were independent of the expert who provided the rating. One hundred percent agreed that there was no particular participant in the expert panel who was more competent than the rest.
Reliability: Two questions targeted the reliability of the assessments. Question 7 asked if timing was independent of the role it played in the outcome of the assessments. Sixty-four percent responded that timing did not play a role in their ratings, and the assessments should be valid at any time. Question 12 asked if any equivalent form of assessment would be useful. Forty-two percent responded that it would be useful. One participant commented that a standards form would be beneficial.
Substantive: Question 18 dealt with assessment substance. Specifically it asked if the assessments specifically required expert or tacit knowledge or if a routinely trained employee without the associated experience would have been able to rate the comments equally. Ninety percent agreed that routinely trained employees would have produced similar results.
Practicality: Question 2 asked if the assessments were recognized by others in the organization. Only 33% agreed that managers and trainers would find these assessments relevant. Question 3 asked the participants to rate the cost-effectiveness of the assessment. Forty-three percent responded that cost-effectiveness was good, while 57% stated that it was fair. No participants stated that it was ineffective. Question 17 asked for the overall satisfaction of the assessments. One hundred percent responded that they found the expert ratings to be sufficient.
Generalizability: Evidence that the assessments can be generalized is important to the first research question in this study. Question 13 asked if the assessment would be contaminated by incentives of other forms of motivation. Forty percent said that it was a possibility. Question 14 asked if the assessment process could be used for other purposes other than this study. Sixty-three percent responded that they thought it would be possible. Question 16 asked if factors not strictly related to the job could influence the assessment such as ethnicity, gender, or age. No participants responded that these factors would play a role in the assessment outcomes.
Consequential: The final form of evidence dealt with the social aspects of the assessments as they related to the expert panel participants. Question 15 asked if there was an impact on the participants outside the job-related aspects. In particular, it asked if the anonymity helped alleviate any social pressures. Only 36% said that the participants may feel some social pressure despite not being directly identifiable in the assessment process.
After the Delphi had been completed, three sets of data were produced that would provide answers to the research questions posed in this study. The first question attempted to determine if the assessment process was repeatable, so a quantitative and a qualitative process were used. The second research question tested the overall value of the handwritten notes, and only a quantitative test was performed.
For the first question, the researcher used a t-test for the quantitative analysis that compared the grand means of the value indicators for each of the two repositories. This results of this test showed that for a 99% confidence rating, the two repositories did not have significant statistical differences.
The qualitative analysis for the assessment was tested using a survey created by Thomson, et al. (2001) that was given to the expert panel after the rating process had finished. The questions corresponded to forms of evidence proposed by Nitko (1996) and targeted areas of concern regarding the validity of the assessment process. Overall the process was found to be beneficial by the expert panel, and provided evidence that the process was effective and could be generalized beyond this study.
For the second question, the quantitative analysis was in the form of an expert defined metric that would determine the overall value of the repository. The metric dictated that 50% of the ratings must have a value of ‘four’ or above. The first repository had a value of 29%, and the second was 46% resulting in a combined average of 37%.
Chapter 5
Conclusion, Implications, Recommendations, and Summary
The conclusions for this study connect the relevant literature to the research questions answers in the previous chapter. This section is broken down into discussion about work orders and technologies for transcription, organizational benefits, concerns, limitations, and future implementations.
Work Orders and Transcription Technology
The goal of this study was to determine the value of handwritten comments in the work place. In this context the handwritten notes were found on work orders completed during tasks in the field by qualified employees. These work orders had been archived for years but were never referenced after their initial use. Certain aspects of the organization’s information had been in a digital form, but mainly related to current tasks and were removed after the job was performed. Since the work orders contained additional comments relating to conditions of the task and not directly to the original work, there was potential for additional knowledge extraction.
During the qualitative analysis, the work order assessment was studied for its representation of the repository topic. Since the work orders were deemed to be an important portion of the organizational knowledge-base, the expert panel was asked to rate this representation. A majority agreed that it was a good representation of the overall topic. They found that the work order comments adequately covered the many aspects involved with the task, and also agreed that the comments reflected the current work practice performed in the associated tasks. Despite the agreement that the current work orders portray the topic well, some experts pointed out a few shortcomings. The comments while generally reflecting common work practice did not convey the lack of manpower that is often found to be a limiting factor to performing the tasks. Additionally the comments were found to primarily target worst case scenarios, which may overemphasize some situations more than others.
The contents of work orders could be improved with some additional criteria as well. A general need for more detailed information was reported by the expert panel with over half stating that more details would improve comment quality. Brief notations regarding the organization and scheduling aspects of the tasks were identified as possibly adding some clarity to the work orders. Similarly, prioritization was another suggested improvement in order to help comments become more useful. Fewer thought that anything should be removed from the work order comments, and there were no specifics identified. Unanimous agreement was reached when asked if the expert analysis was sufficient for the repository as a whole.
Another aspect of work orders was the issue of practicality. While it was determined that the expert panel generally agreed with the overall usefulness of the comments, they thought that other entities may not favor the comments as much. The comments were not perceived to be relevant to upper management and trainers, who may not fully understand the level of effort portrayed in the work orders. Over half of the participants rated the cost-effectiveness of assessing the comments as only fair. These opinions convey an overall feeling that the work order comments are useful for the technicians, but possibly less so for employees who assess their performance. Cost was found an issue, as current budgets are limited and spending time, effort, and money on reviewing these comments may become a constraint on the department.
The issue of cost effectiveness would vary depending on the transcription process. The technology for transcription of handwritten notes has not matured to the point of mainstream usability at this point according to Callan, et al (2002). In order to bypass this technical limitation, the researcher manually transcribed the work order comments into a spreadsheet. This process took several days consisting of two to three hour sessions for completion of the entire repository. Had this task been moved onto the organization’s staff, the resources that were already limited would face additional barriers to implementation.
Progress is being made towards this goal, and some technologies are emerging that may provide a valid solution to the inherent difficulty that transcribing handwriting presents. Howe, et al. (2005) have successfully transcribed historical scripts from museum archives. This achievement provides proof that writing can be interpreted even if not in a typed format and read through optical character recognition.
The work performed by Howe, et al. dealt with handwriting that was presented in a traditionally uniform format. Historical text interpretation was found to produce more accurate results since the writing by the original authors was more deliberate and more time was spent when writing compared to modern handwriting. Govindaraju, et al. (2009) also targeted handwriting recognition, but analyzed notes written in a medical emergency room. These notes posed many difficulties since they were written quickly, contained complex terminology, and the authors often had poor handwriting. Despite these issues, the authors were able to find similarities and patterns that allowed for some transcription to occur. Once this form of technology becomes more stable and automated, the transcription process should become less of a cost concern.
The survey targeted some concerns and possible benefits with the process. Internal coherence and external consistency raised several issues with the process. Internally, some comments possessed the ability to span topics. Since the ratings typically cover a single concept, there is a concern over the validity of covering both with a single value. The experts were asked if the ratings would be consistent if the topics were extracted and rated individually. A majority agreed that this would still be the case.
Externally the assessments pose a concern over their validity outside the specific environment use for the study. The assessments were first compared to other forms of task assessment. Experts were asked to judge the level of consistency between rating the work order comments and other measures of assessment regarding their performance. Most responded that their work order comment ratings were consistent with other forms. The participants were then asked if they considered the assessments to be beneficial to an outside group reviewing the data from the assessments. Over half agreed that others would find the data beneficial, with one participant adding that there would need to be some additional context added however. A follow-up question asked if there was a specific expert in the panel who was integral to the rating process. This implementation of the Delphi process allows for participants who are more knowledgeable about a certain topic to provide some additional insight, so this concern is not as great. However all participants stated that the rating process could have been completed with other members, and no specific individual became the deciding factor.
Reliability and substance also were identified as concerns. Similar to the questions posed regarding the need for specialized experts, the survey asked if a routinely trained employee would be able to assess in the same capacity as an expert with first hand experience. A majority agreed that employees could be trained to the point where their assessments would be consistent with the experts’. While this lessens the importance of tactic knowledge, it does lend to the repeatability of the process. If the process was to be repeated, the timing of the assessments was also considered. If the assessments could differ based on the time they were performed, that would impact the ability for this process to be consistently applied. Almost two-thirds agreed that it was timing independent. This percentage does not indicate a complete agreement and still presents concern over the timeliness of the assessment, but is still consists of a majority.
Secondary factors were also considered. Motivation can be used to get participants to partake in a study. Although coffee and minor refreshments were used as a form of compensation, the expert panel was comprised of volunteers, so participation should not have been due to the promise of a reward or contamination through some other motivation. Despite this, just under half of the panel still said there could be a chance that motivation played a role in getting the expert panel to participate. This could be due in part to feelings of obligation from management in the organization.
Another question asked about social pressure, and a minority of the participants said there was some impact, however minor, due to the assessment process. Despite anonymity, some still felt pressure to a degree. Other factors that were identified related to social concerns such as ethnicity, gender, or age. These factors should not have any effect on the consistency of the ratings, but the survey asked the participants if they thought that this was still true. No participants responded that any of these factors would affect the assessment process.
In addition to the structured survey questions, the researcher observed that time commitment was found to be another concern within this study. While the researcher was required to spend a substantial amount of time performing manual data entry processes, the expert panel’s time posed a challenge to obtain. Despite the researcher’s activities taking up more time than the expert panel’s, it became a barrier to coordinate the participation of 20 individuals on multiple occasions.
The expert panel agreed to participant, but found that filling out the rubrics took almost and hour. They had to forfeit their lunch hour in some cases or fit the rating process into their already busy work schedule. The combination of these choices often meant the researcher had to persistently check with the group in order to get the data returned in a timely manner. Subsequent sessions were met with greater hesitation due to the previous time commitments and the amount of sessions required overall. The study was completed successfully, but future implementations would most likely have to pursue a different method of gathering an expert panel.
The primary limitation that this study encountered was the similarity of the document repositories. In order to eliminate variables, two document sets of work orders were chosen from the same topic and differed only by year. This produced similar rating results as evident by the findings in the results chapter. While this was not determined to be a detriment to the study and was even preferable when testing repeatability, it may be beneficial to test how the implementation performs on a repository with a differing topic.
During the final survey, the expert panel was asked about the generalizability of the assessments. Since the first research question concentrated on this issue, getting a qualitative response from the participants was one way to address the concern. When asked, over half responded that they thought the assessment process could be used on other repositories and topics. The participants had conveyed that assessments were independent of the specific experts who rating them. Additionally timing was found to not affect consistency and the majority of the panel agreed that the current model didn’t need to omit any assessment ratings in order to remain valid.
Future implementations would benefit from exploring additional variables. As stated, one limitation was repository diversity, but other aspects could be changed such as expert panel size, document count, and field of study. The expert panel in this study consisted of 20 participants, but per the suggestion by Clayton (1997), this could be increased to 30. A separate group of participants may also provide new insights to the rating process, but may increase the concerns relating to time constraints.
Repository size could be increased in order to cover a broader collection of work orders. This suggestion may not prove as effective as others due to the similarity between the previous repository sizes, both which met or exceeded the recommended volume to generate a normal distribution as dictated by Ott (1992).
The greatest difference which could be tested would be change the field of study. Testing on a new discipline would require several changes to the remainder of the study and would allow for a different analysis. Value indicators would inherently change to accommodate the new repository topic, and the expert panel would also be a different set of participants. This combination should further test the generalizability of the study.
In order to assess the implications of this study, the researcher asked two research questions. The first determined the repeatability of the expert assessment process, and is discussed in the contributions sections. The second question determined the overall usefulness of the handwritten notes as a valid source of knowledge and is discussed in the impact section. Proposed changes are discussed in the future implementations section.
This study has attempted to implement a repeatable and general procedure for rating handwritten work order comments and assess their value. The researcher analyzed the effectiveness of the choice to use a Delphi group technique though the use of quantitative and qualitative tests. The Delphi utilized the recursive assessments of an expert panel to arrive at a consensus, so validation of the process would help contribute some assurance to the technique.
The researcher performed a t-test to compare the means of each tested repository for statistical significant difference. At the 99% confidence interval, the differences were not statistically significant, and the null hypothesis was not rejected. This lack of difference provides evidence that the repository ratings and assessment process remain within statistically similar limits when performed a second time using the same expert panel and the same topic.
The results from the qualitative survey helped provide some expert insight to the work order assessment process. This allowed the researcher to gather opinions that were not strictly numerical but rather from human experience and intuition. Overall the process was considered to be generalizable when considering the use of experts to achieve consensus. All of the participants agreed that while experts were important to performing the rating, there was no specific expert who possessed the key rating in order to generate a sufficient assessment. Furthermore, almost all the participants said that routinely trained employees would become suitable experts and would not need to be directly related to the original tasks. Additionally, no participants thought that outside factors would contaminate the assessments such as gender or ethnicity. If performed outside of the topic, the majority of participants agreed that it would remain consistent, and a similar majority agreed that outside parties would find the assessments useful and that the process could be directly applicable for a purpose other than the one in this study. The majority of the experts found the assessments to cover the topic, reflect work practice, and remain consistent with other forms of job assessments.
The negative responses were generally fewer than the positive feedback. Almost half of the participants said that motivation could contaminate the assessment process. These opinions are assumed to be hypothetical regarding the assessment process in general as no incentives were offered in this study other than light refreshments, but there was the possibility of perceived management pressure acting as a motivator. One-third of the panel also thought that despite anonymity, they felt some personal social pressure during the assessment. Despite these negative aspects and the moderate statistically significant difference in repository mean ratings, the qualitative results from the expert panel portray a process that is repeatable and generalizable across topics, studies, and organizations.
While the impact on the organization relating to the actual usefulness of the work order comments is primarily determined by analyzing the raw rating data, some of the qualitative survey answers provided insight to the experts’ opinions. The first research question had an overall positive result in regards to the assessment process, but the second research question resulted in moderate to fair results regarding the actual findings. Independent of the raw rating assessments, only one-third of the experts thought that upper management and trainers would find these assessments relevant. The panel also had some cost concerns with the process. No one found the assessment to be explicitly cost ineffective, but over half thought that it was only fair with the remainder stating that it was good. Regardless of the final value, the process might become a barrier to the ultimate acceptance of a knowledge extraction procedure.
When analyzing the raw ratings based on the metrics proposed by the majority of the expert panel, the overall results portrayed similar concerns. The first repository had 29% of documents higher than a score of ‘four’ out of 10, while the second had 46% resulting in a combined score of 37%. In both cases, the environmental concerns were rated much lower than cost, man-hours, and condition. Repository 1 was well under the minimum percentage for all value indicators, but the second had one rating average above the minimum and two at 50% and 49%. However since the final value indicators were determined by the expert panel to be the basis for assessing value, the overall score is considered below the designated threshold. This indicates that these repositories lack the necessary overall value when analyzed as a whole unit.
Future Implementations
Future implementations of this study would address the shortcomings found during the answering of the research questions. The issues presented in the first research question are straightforward and relate to adjustments that can be made in the assessment process. During the process, participants stated that pressure or motivation may have had influence on the assessments. For the purpose of this study, experts were selected by a supervisor. This was decided per the suggestion by Aggarwal, et al. (2005) that supervisors possess the ability to select valid participants. However the experts had been defined as individuals with relevant field experience, and it would be possible to directly approach qualified experts on an individual basis creating a completely anonymous expert panel as opposed to the anonymity being relegated solely to the assessments. This should also alleviate any social concerns if the expert panel thinks that they will not be known for their answers as well as the fact that they participated.
The other qualitative concern was the cost-effectiveness of the assessment. Twenty experts were used in this study in order to achieve a normalized dataset (Ott, 1992). This number did cause some issue with use of time, and ability to gather the necessary volume of participants. If cost was a concern, a selection of experts who deal with the topic on a more individual basis may reduce the time and cost requirements. While the survey results showed that the expert panel agreed that any routinely trained employee would be an acceptable assessor, this would provide a balance between the data collected and the effort to collect. A total of at least fifteen experts were suggested to be the minimum for the assessment, but a qualified supervisor would be able to determine a smaller yet equally valid expert panel.
The quantitative results provided less opportunity for alteration, since they were the outcomes of the actual data. For this study, the value indicators were proposed by the expert panel, and the methodology required the final proposals to become part of the rubric. On all accounts, the environmental value indicator column had overall results much lower than the others. However since environmental concerns were a valid indicator of value according to the expert panel, it should be considered more of an observation than a barrier to the overall assessment of the repository value.
Recommendations are based directly upon the two research questions. Two main areas of interest have been the focus of this study: the assessment process and the overall value of the handwritten work order comments. The Delphi technique used for the assessment was generally agreed by the expert panel to be an acceptable method for repeatedly rating work order comments. Responses indicated that it would also be generalizable to other organizations, topics, or tasks. The quantitative results compared the grand means of the repositories and found no statistically significant difference. Little would need to change when using the Delphi aside from some cost saving measures. The transcription process was performed by the researcher, so that did not factor into the experts’ opinions. However concerns over direct costs relating to the rating process could be improved based on suggestions from the supervisor.
The second area of concern is the value of the work order comments within the chosen repository. The goal if this study was to determine the usefulness of the comments and in turn see if continued evaluation would be a beneficial process. Despite the assessment process being appropriate, the evaluation was only used to determine initial value. The usefulness of the repository would then become the factor that would dictate future transcription and use. The cost concerns relating to the assessment process would no longer be an issue, but the greater cost of transcription would be. At this point in time, the technology remains a barrier since automated procedures are not mature. Gathering historical work order comments will most likely be a difficult task until such procedures can be automated.
Without taking cost into consideration, the recommendations for continuing this process rely more on the determined value of the repository. The expert panel identified key indications of value in order to rate the work order comments. Of these, one indicator could be found to be lower than the rest and bring the overall value of the repository down. While a low value indicator cannot be arbitrarily thrown out, it may be beneficial to discuss the weight each indicator has on the repository and determine if the repository should still be considered valuable despite one low category.
In order to provide further recommendations, the researcher would need to determine if the repositories contain value and are worth the effort to capture and extract knowledge. The final value for the repositories was found to be below the minimum level of value designated by the metrics, so if a great amount of effort to capture this knowledge in a formalized or digital format is required, it would most likely not be worth the effort to continue the process. Manually transcribing the historical comments would present a great effort to both cost and efficiency. If technological advances allow for an automated process, this concern may not be as great, however the effort required would still need to be justified.
Capturing new comments as they are created might be a better way to continue. There is some value to the comments, so the method of utilizing them will play a role in their ultimate use. It may be beneficial to capture the comments as they are returned from the onsite task. This will alleviate the large backlog of paper documents that both take up space and present a larger transcription task as a later time. A recommendation to eliminate paper altogether might also be feasible. Onsite digital devices could record comments directly into a database. With these suggestions, the content of the comments are retained but lack the barriers that physical paper presents.
The final consideration is the decision to keep or discard existing paper documents. Paper takes up space and is difficult to data mine, so removing this burden might be a beneficial choice of action. A general statement as to the value of all repositories cannot be made from the results of this study given the low to borderline ratings for the two samples. However a valid assessment procedure has been identified should the organization decide to continue on an individual repository basis. To alleviate some burden, one possibility might be to extract a sample subset of documents and then test this subset using a smaller expert panel in order to lessen the cost and time commitments. The results of this abridged assessment might warrant the continuation or abandonment of further transcription.
Based on the premise that handwritten notes are created in the workplace but seldom referenced or used, this study attempted to evaluate the value of these notes by utilizing the skill of an expert panel and performing both qualitative and quantitative tests. This evaluative study was built upon research by Liu & Fidel (2007) who assessed tacit verbal knowledge in the workplace. To perform the methodology, the researcher adopted an implementation of the Delphi group technique validated by Goldman, et al. (2008) while supplementing core recommendations by Linstone & Turoff (2002) for determination of the final consensus.
To provide a foundation for the goals in this study, a review of the literature was performed. This review covered areas of concern in regards to the aging workforce, paper-based storage, data extraction and knowledge acquisition, difficulties with tactic knowledge, and character recognition. The primary concerns were the loss of knowledge due to employee retirement or leave, knowledge collection and storage, and methods of accessing knowledge once stored.
The aging workforce poses a threat to knowledge loss, since older and more experienced employees retain years of knowledge but are more likely to leave the organization due to retirement or other leave. Hafida (2008) identified the fact that the loss of these employees removed the ability to utilize their experience for job related tasks. Fadel, et al. (2008) expanded on this topic by describing the gap that occurs between new and veteran employees. New hires had a tendency to only learn what is needed for the immediate job. If new knowledge was needed, they could learn from a more experienced employee, but this caused an issue when that veteran employee was no longer present. Liu & Fidel (2007) added that this problem is complicated because that veteran employees are less willing to part with their knowledge as it is perceived as job security. New employees are more willing to share, but possess less knowledge.
Collaboration of knowledge was then researched to determine the most appropriate methods of solving the problem of knowledge loss. Employee participation was found to be a difficult barrier. Bossen & Dalsgaard (2005) and Makolm, et al. (2007) described collaborative systems that were either bypassed, modified, or avoided. The systems described by the authors attempted to be transparent to the users or remain intuitive, however user involvement was met with opposition if it caused more work than the employees expected. Mobile environments were found to be more accepted since they enhanced the ease of tasks rather than present a hindrance. Bortenschlager, et al. (2007) described the benefits of a mobile environment at the expense of a formal structured system. The unstructured setting did provide some fault tolerance, however, and alleviated the need for a central fixed office.
Repositories formed a part of the collaboration process. As knowledge became explicit information and was stored, there was a need to retrieve and reference the contents of the repository. Volume was a primary concern as Mikeal, et al. (2009) described. Tagging and strictly regulated metadata was important to manage a large collection of documents. Lack of organization affected searching efficiency when repositories grew. This was especially noticeable in document sets that were gathered from informal sources such as e-mail and word processors since there were minimal associated search criteria (Aman & Babar, 2009).
Paper-based storage added an additional layer of complexity since digital search methods are not possible. While there are some benefits such as portability and the lack of multiple and possibly redundant copies (Jervis & Masoodian, 2009), organization becomes difficult. Steimle (2009) recognized that paper is still a valuable resource, but digitization is also critical for proper utilization of the repository. The author described a system where traditional paper documents were immediately converted into digital documents. Revisions to these documents were subject to the same system and were reflected in the resulting documents. Konishi, et al. (2007) further described the process of maintaining both paper and digital counterparts. New technology such as the Anoto digital pen was used in many cases to combine traditional input techniques with modern digital functionality.
Handwriting posed the most difficult barrier since it lacks much of the structure inherent with typed text. Historical text did not have as many concerns regarding legibility as Howe, et al. (2005) found. However Govindaraju, et al. (2009) targeted medical notes, which were both considerably illegible and contained complex terminology. However pattern recognition still showed promising results towards interpreting this type of handwritten documentation.
For this study, two research questions were asked in order to validate the research goals. The first focused on determining if the expert review process was repeatable and generalizable. The second attempted to place overall value and determine if the repositories were a valuable source of knowledge acquisition. To test these questions, two null hypotheses and a survey were used. The survey analyzed the first research question in a qualitative manner in order to collect expert opinion on the assessment process. A t-test of statistical similarity was also used to reach a quantitative conclusion towards the difference between two sample repositories and their associated assessment. The null hypothesis stated that there should be no statistical difference. The second research question was tested based on a metric created and defined by the expert panel in order to quantifiably determine the overall value of the repositories. The hypothesis stated that the overall value as defined by the expert panel should be above the minimum threshold that was also defined by the expert panel.
To test these hypotheses and answer the research questions, an expert review process was used. In this study the Delphi group technique was chosen since it did not involve face-to-face interaction between the participants, lessened management pressure, and did not require strict time and location requirements (Linstone & Turoff, 2002). The Delphi consisted of a series of rounds requiring an expert panel to rate a collection of handwritten notes using a rubric that the experts had previously helped create.
The researcher worked with the manager of a public works department to select a group of participants and two repositories. The repositories consisted of work orders that contained handwritten notes that were written in the field. The technology is not mature enough to reliably convert handwriting into usable text, so for this study the researcher manually transcribed the work orders and added them to the rubric as a list of items that would be rated. As part of the initial stages of the Delphi, the panel chose four indicators of value to rate the work order comments. These were cost, man-hours, environmental concerns, and condition. Each value indicator was added to the rubric, and the expert panel was asked to rate each comment on a scale of zero to ten.
After each rating round, the researcher averaged the ratings and created a new rubric with the existing items and new averages for reference. After the second round, the results were tested for consensus. Both repositories required a third round before the change levels were below the threshold defined by Linstone & Turoff (2002). The raw data from both assessed repositories were used to test the research questions. The grand mean of the individual rating averages was first compared between both repositories using a t-test. At the 99% confidence level dictated in the methodology, the difference was not statistically difference, so the null hypothesis was not rejected. The expert panel was also given a survey created by Thomson, et al. (2001) for the purpose of validating the assessment process. The results were compared with eight forms of evidence defined by Nitko (1996). The overall consensus was that the process was thought to be repeatable and generalized for other expert groups and topics. The survey and t-test provided positive conclusions for the first research question.
The second research question was determined by metrics defined by the expert panel. In the first stages of the Delphi, the panel concluded that the repositories would be considered valuable if at least 50% of the work order comments were rated ‘four’ or above. Between the two test repositories, only 37% of the comments reach this threshold. Although the assessment process was confirmed to be adequate, the overall repository value was not found to be sufficient.
The final conclusion was that the process of using an expert panel to rate the work orders was valid and repeatable, however the repositories assessed in this study were found not have sufficient value. Future research would test this procedure on different topics and with different expert panels, and due to the conclusion that the assessment process was valid; alternate panels may choose different criteria and have different results. In addition to the value of the documents, there was some concern over the cost effectiveness of the data collection. In time, the technology for handwriting recognition will improve and provide a streamlined approach towards capturing these notations. This should alleviate some of the concerns and provide an efficient procedure for assessing handwritten comments.
Appendix A
![]() Permission to Perform Study Off-Site
Permission to Perform Study Off-Site
Appendix B
Sample Rubric (Round 1)
|
Please rate the following comments on a scale of 0-10 for estimated importance. |
||||
|
Cost = Estimated monetary concern |
Environmental = Impact on surroundings |
|||
|
Manhours = Estimated labor involved |
Condition = Physical structure of outfall |
|||
|
Comment |
Cost |
Manhours |
Environ |
Condition |
|
Water running clean. No pipe visible. |
|
|
|
|
|
Hand digging and clear brush. |
|
|
|
|
|
Clear, dead end in yard. |
|
|
|
|
|
Need to be trimmed back brush at end of pipe. |
|
|
|
|
|
Cleared leaves |
|
|
|
|
|
Cleaned leaves out |
|
|
|
|
|
Cleaned out brush |
|
|
|
|
|
Needs to be cleaned backhoe |
|
|
|
|
|
Backho work on northside of Glen Road |
|
|
|
|
|
Pipe underwater, still running |
|
|
|
|
|
Shoveled sand and moved rocks. |
|
|
|
|
|
Drain gate cleaned off, rip rap |
|
|
|
|
|
Backho work on northside of Glen Road |
|
|
|
|
|
Needs to be cleaned, backho. |
|
|
|
|
|
Pipe underwater and running into stream onto beach. |
|
|
|
|
|
Underwater |
|
|
|
|
|
Ditch full of water. |
|
|
|
|
|
Pipe underwater |
|
|
|
|
|
Needs cleaning |
|
|
|
|
|
Pipe blocked off per order of lot owner. Makes puddle in road. |
|
|
|
|
|
Needs sand removed, pipe half underwater. |
|
|
|
|
|
Ditch full of sand. Can be done by machine. |
|
|
|
|
|
Removed sand from end of pipe. Can be done by machine. |
|
|
|
|
|
Needs sand removed. Some trimming can be done by machine. |
|
|
|
|
|
Needs cleaning, machine |
|
|
|
|
|
Cleaned out branches mud and feathers. |
|
|
|
|
|
Shovel sand and cleared out rocks. |
|
|
|
|
|
Ditch water is running. About 50' of ditch weeds to be cleaned and trimmed. Machine |
|
|
|
|
|
State basins. Draw out on beach. |
|
|
|
|
|
Not working anymore. Use to drain from Cove Street. |
|
|
|
|
Appendix C
Sample Rubric (Round 2+)
|
Please rate the following comments on a scale of 0-10 for estimate importance. |
||||||||||||
|
Cost = Estimated monetary concern |
Environmental = Impact on surroundings |
|||||||||||
|
Manhours = Estimated labor |
Condition = Physical structure of outfall |
|||||||||||
|
A = Average from previous session |
R = Median Range. Please comment if outside these values |
|||||||||||
|
Comment |
Cost |
Manhours |
Environ |
Condition |
||||||||
|
|
A |
R |
|
A |
R |
|
A |
R |
|
A |
R |
|
|
Water running clean. No pipe visible. |
3.2 |
1 - 5 |
|
3.4 |
1 - 6 |
|
2.9 |
1 - 5 |
|
3.3 |
2 - 5 |
|
|
Hand digging and clear brush. |
4.3 |
3 - 6 |
|
5.0 |
4 - 6 |
|
3.7 |
1 - 6 |
|
4.4 |
3 - 6 |
|
|
Clear, dead end in yard. |
3.0 |
1 - 5 |
|
2.8 |
1 - 4 |
|
2.9 |
1 - 5 |
|
3.5 |
1 - 6 |
|
|
Need to be trimmed back brush at end of pipe. |
3.3 |
2 - 4 |
|
4.0 |
3 - 5 |
|
3.1 |
1 - 5 |
|
3.7 |
2 - 5 |
|
|
Cleared leaves |
2.6 |
1 - 4 |
|
2.3 |
1 - 3 |
|
2.6 |
1 - 3 |
|
2.7 |
1 - 4 |
|
|
Cleaned leaves out |
2.3 |
1 - 3 |
|
2.7 |
2 - 3 |
|
2.4 |
0 - 4 |
|
2.7 |
0 - 5 |
|
|
Cleaned out brush |
2.9 |
1 - 3 |
|
3.2 |
2 - 4 |
|
2.6 |
0 - 5 |
|
2.5 |
1 - 4 |
|
|
Needs to be cleaned backhoe |
5.4 |
3 - 8 |
|
5.1 |
3 - 8 |
|
3.8 |
2 - 5 |
|
4.6 |
2 - 7 |
|
|
Backho work on northside of Glen Road |
5.7 |
4 - 8 |
|
5.5 |
4 - 8 |
|
4.1 |
3 - 5 |
|
4.7 |
3 - 6 |
|
|
Pipe underwater, still running |
3.7 |
1 - 5 |
|
3.3 |
1 - 4 |
|
3.2 |
1 - 5 |
|
4.0 |
2 - 6 |
|
|
Shoveled sand and moved rocks. |
3.6 |
2 - 5 |
|
4.0 |
3 - 5 |
|
2.9 |
0 - 5 |
|
3.1 |
1 - 5 |
|
|
Drain gate cleaned off, rip rap |
2.7 |
1 - 3 |
|
3.3 |
2 - 5 |
|
2.6 |
1 - 3 |
|
3.5 |
1 - 5 |
|
|
Backho work on northside of Glen Road |
5.7 |
4 - 8 |
|
5.4 |
3 - 8 |
|
3.7 |
2 - 5 |
|
4.4 |
3 - 6 |
|
|
Needs to be cleaned, backho. |
5.0 |
3 - 8 |
|
5.0 |
3 - 8 |
|
4.0 |
2 - 6 |
|
4.7 |
3 - 6 |
|
|
Pipe underwater and running into stream onto beach. |
4.7 |
3 - 6 |
|
4.4 |
3 - 6 |
|
5.2 |
3 - 8 |
|
4.1 |
2 - 6 |
|
|
Underwater |
4.1 |
1 - 6 |
|
4.1 |
2 - 6 |
|
4.6 |
1 - 8 |
|
5.0 |
2 - 8 |
|
|
Ditch full of water. |
4.1 |
2 - 6 |
|
4.5 |
3 - 6 |
|
4.1 |
2 - 6 |
|
4.4 |
2 - 7 |
|
|
Pipe underwater |
4.2 |
2 - 6 |
|
4.5 |
2 - 8 |
|
4.5 |
1 - 7 |
|
4.7 |
1 - 7 |
|
|
Needs cleaning |
4.1 |
2 - 6 |
|
3.9 |
2 - 5 |
|
3.8 |
1 - 5 |
|
4.1 |
2 - 5 |
|
|
Pipe blocked off per order of lot owner. Makes puddle in road. |
5.2 |
4 - 7 |
|
4.7 |
3 - 7 |
|
4.9 |
2 - 8 |
|
5.0 |
2 - 7 |
|
|
Needs sand removed, pipe half underwater. |
4.7 |
3 - 7 |
|
5.2 |
3 - 7 |
|
4.9 |
3 - 7 |
|
4.6 |
2 - 7 |
|
|
Ditch full of sand. Can be done by machine. |
4.1 |
3 - 6 |
|
4.6 |
3 - 6 |
|
3.9 |
2 - 6 |
|
4.1 |
2 - 6 |
|
|
Removed sand from end of pipe. Can be done by machine. |
4.4 |
3 - 6 |
|
4.7 |
3 - 6 |
|
4.2 |
2 - 6 |
|
3.9 |
2 - 6 |
|
|
Needs sand removed. Some trimming can be done by machine. |
4.5 |
3 - 6 |
|
5.0 |
4 - 6 |
|
3.9 |
2 - 5 |
|
4.1 |
2 - 6 |
|
|
Needs cleaning, machine |
4.6 |
3 - 6 |
|
5.0 |
3 - 6 |
|
4.4 |
3 - 6 |
|
4.6 |
2 - 6 |
|
|
Cleaned out branches mud and feathers. |
3.3 |
2 - 4 |
|
3.7 |
2 - 5 |
|
4.4 |
3 - 6 |
|
3.9 |
2 - 6 |
|
|
Shovel sand and cleared out rocks. |
3.1 |
1 - 4 |
|
4.0 |
2 - 6 |
|
3.2 |
1 - 5 |
|
3.5 |
1 - 5 |
|
Appendix D
Assessment Survey
Items in parenthesis are notations by the researcher and are added for clarification.
1. Do the assessments used in your company cover all or only some of the content of your training program?
(For this repository, do your assessments represent the entire topic?)
2. Are your company’s assessments recognized by all relevant groups and individuals (management, trainers, assessors and trainees) as being appropriate?
3. How would you rate the cost-effectiveness of the assessments?
(Specifically: monetary, safety, labor, other ‘costs’…)
4. Can you say with confidence that your assessments consistently reflect work practice?
5. Do you think any additional assessment is needed?
If so, what would this be?
6. Could any assessments or parts of assessments be omitted?
If so, what would this be?
7. Are the outcomes of your assessment independent of the timing of the assessment?
(Would your assessments remain consistent if performed at another time?)
8. Where different assessment tasks have some overlap in content, are the assessment outcomes from the different tasks consistent?
(For assessments affecting two topics, would they be equally accurate if performed separately?)
9. Are the outcomes of the assessment tasks consistent with other evidence such as work assessments or third-party verification (testimonials)?
(Would your assessments remain consistent if performed outside this study?)
10. Do the outcomes of the assessments tasks satisfactorily predict employment success in terms of further learning (either on or off the job)?
(Would others benefit from learning from the work order comments, based on your assessments?)
11. Are assessments graded in any way, e.g. to identify those who are ‘very competent’ rather than just ‘competent’? How is this done? Are the outcomes of the assessment tasks independent of the assessor(s)?
(Specifically in this case, when comments were provided to explain expert ratings outside the central range of previous responses, were the comments beneficial for revising your future ratings?)
12. Would it be useful to have equivalent forms of the assessment tasks available? (Would another form of assessment have been more appropriate for assessing the work order comments?)
13. Can the outcomes for an individual assessor on an assessment task be affected by incentives, special forms of motivation, etc.
14. Can you think of any examples where the results of an assessment have been used for purposes other than those for which they were designed?
(Do you feel this assessment could be used for any other purpose than to rate work order comments?)
15. Following on from the above, can you think of any cases where there are social consequences for the assessor, not related to the work-specific purpose of the assessment?
(Since the ratings were submitted anonymously, do you feel that helped address any social concerns?)
16. Continuing in this area, can you think of any assessment tasks where the outcomes may be influenced by factors not strictly relevant to the job, such as ethnicity, gender, socio-economic status, age?
17. Are you satisfied with the assessment skills of the available assessors, in terms of their ability to implement the assessment procedures?
(When revising your ratings, did you find the ratings average from the expert panel to be sufficient?)
18. Do the assessment tasks include the application of thinking skills other than rote learning?
(Due to the nature of your work, did you find the assessment required ‘expert’ skill, or would routinely training employees have produced similar results?)
Appendix E
Permission to Use Survey
Dear Daniel
Thank you for your email.
Permission is granted to implement a modified version of the survey found in the NCVER publication Improving the Validity of Competency-based Assessment (2001) by Peter Thomson, Saunders and Foyster for educational purposes. We do request that NCVER is cited as the source.
If you have any further queries, please don't hesitate to contact me.
Kind regards
June Ingham
Events & Administration Coordinator, Marketing Services
National Centre for Vocational Education Research (NCVER)
Level 11, 33 King William Street
ADELAIDE SA 5000
Phone: (08) 8230 8491
Fax: (08) 8212 3436
Web: www.ncver.edu.au
Appendix F
Correlation Between Questions and Evidence
Nitko (1996) outlines eight forms of evidence that provide validation to expert assessment instruments. Each form of evidence is addressed by one or more survey question outlined in Appendix A. A mapping of the correlation is below.
|
Evidence |
Survey Question |
|
Representation of Evidence |
1. Do the assessments used in your company cover all or only some of the content of your training program? 4. Can you say with confidence that your assessments consistently reflect work practice? 5. Do you think any additional assessment is needed? 6. Could any assessments or parts of assessments be omitted? |
|
Internal Coherence |
8. Where different assessment tasks have some overlap in content, are the assessment outcomes from the different tasks consistent? |
|
External Consistency |
9. Are the outcomes of the assessment tasks consistent with other evidence such as work assessments or third-party verification (testimonials)? 10. Do the outcomes of the assessments tasks satisfactorily predict employment success in terms of further learning (either on or off the job)? 11.Are assessments graded in any way, e.g. to identify those who are ‘very competent’ rather than just ‘competent’? How is this done? Are the outcomes of the assessment tasks independent of the assessor(s)? |
|
Reliability |
7. Are the outcomes of your assessment independent of the timing of the assessment?
12. Would it be useful to have equivalent forms of the assessment tasks available? (Would another form of assessment have been more appropriate for assessing the work order comments?) |
|
Substantive |
18. Do the assessment tasks include the application of thinking skills other than rote learning? |
|
Practicality |
2. Are your company’s assessments recognized by all relevant groups and individuals (management, trainers, assessors and trainees) as being appropriate? 3. How would you rate the cost-effectiveness of the assessments? 17. Are you satisfied with the assessment skills of the available assessors, in terms of their ability to implement the assessment procedures? |
|
Generalizability |
13. Can the outcomes for an individual assessor on an assessment task be affected by incentives, special forms of motivation, etc. 14. Can you think of any examples where the results of an assessment have been used for purposes other than those for which they were designed? 16. Continuing in this area, can you think of any assessment tasks where the outcomes may be influenced by factors not strictly relevant to the job, such as ethnicity, gender, socio-economic status, age? |
|
Consequential |
15. Following on from [#14], can you think of any cases where there are social consequences for the assessor, not related to the work-specific purpose of the assessment? |
Appendix G
Survey Results
|
Form of Evidence |
Discussion |
|
|
Do the assessments used in your company cover all or only some of the content of your training program? |
Representation of Evidence |
A majority (86%) agreed that the assessments covered the topic. |
|
Are your company’s assessments recognized by all relevant groups and individuals (management, trainers, assessors and trainees) as being appropriate? |
Practicality |
One-third (33%) of the participants who responded thought that upper management would confirm their assessments. |
|
How would you rate the cost-effectiveness of the assessments? |
Practicality |
Less than half (43%) responded that the cost effectiveness was ‘good’, while the remainder found it to be ‘fair’. No experts responded negatively. |
|
Can you say with confidence that your assessments consistently reflect work practice? |
Representation of Evidence |
A majority (73%) agreed that the standard work practice mirrors the results of the assessment. |
|
Do you think any additional assessment is needed? |
Representation of Evidence |
Over half (60%) stated that some additional assessment would make the process stronger. |
|
Could any assessments or parts of assessments be omitted? |
Representation of Evidence |
Less than a third (27%) thought that portions of existing assessment should be removed from the current process. |
|
Are the outcomes of your assessment independent of the timing of the assessment? |
Reliability |
Over half (64%) agreed that the timing was not relevant to the assessment outcomes. |
|
Where different assessment tasks have some overlap in content, are the assessment outcomes from the different tasks consistent? |
Internal Coherence |
A majority (70%) agreed that assessments that overlapped would result in similar outcomes if performed individually. |
|
Question |
Form of Evidence |
Discussion |
|
Are the outcomes of the assessment tasks consistent with other evidence such as work assessments or third-party verification (testimonials)? |
External Consistency |
A large majority (91%) agreed that other assessments outside of this study would produce similar results. |
|
Do the outcomes of the assessments tasks satisfactorily predict employment success in terms of further learning (either on or off the job)? |
External Consistency |
Over half (60%) stated that would assist with future learning processes. |
|
Are assessments graded in any way, e.g. to identify those who are ‘very competent’ rather than just ‘competent’? How is this done? Are the outcomes of the assessment tasks independent of the assessor(s)? |
External Consistency |
All (100%) agreed that other the assessments were not reliant upon a single individual. |
|
Would it be useful to have equivalent forms of the assessment tasks available? |
Reliability |
Less than half (42%) thought a similar form of assessment would need to be performed in parallel. |
|
Can the outcomes for an individual assessor on an assessment task be affected by incentives, special forms of motivation, etc. |
Generalizability |
Less than half (40%) thought the assessments were altered by incentives. Management pressure was stated as a possible concern. |
|
Can you think of any examples where the results of an assessment have been used for purposes other than those for which they were designed? |
Generalizability |
Less than half (45%) thought the assessments would be applicable to topics outside of the current study. |
|
Following on from [#14], can you think of any cases where there are social consequences for the assessor, not related to the work-specific purpose of the assessment?
|
Consequential |
A minority (36%) thought social concerns would affect the outcomes of the assessments. |
|
Question |
Form of Evidence |
Discussion |
|
Continuing in this area, can you think of any assessment tasks where the outcomes may be influenced by factors not strictly relevant to the job? |
Generalizability |
No (0%) participants thought outside factors would affect assessment outcomes. |
|
Are you satisfied with the assessment skills of the available assessors, in terms of their ability to implement the assessment procedures? |
Practicality |
All (100%) were satisfied that the experts provided valid assessments. |
|
Do the assessment tasks include the application of thinking skills other than rote learning? |
Substantive |
A majority (90%) agreed that properly trained employees would report similar assessments as those who had first hand experience in the field. |
Reference List
AbuSafiya, M., & Mazumdar, S. (2004). Accommodating paper in document databases. Paper presented at the Proceedings of the 2004 ACM symposium on Document engineering, Milwaukee, Wisconsin, USA.
Aggarwal, K. K., Yogesh, S., Pravin, C., & Manimala, P. (2005). An expert committee model to estimate lines of code. ACM SIGSOFT Software Engineering Notes 30(5), 1-4.
Aman, U.-h., & Babar, M. A. (2009). Tool support for automating architectural knowledge extraction. Paper presented at the Proceedings of the 2009 ICSE Workshop on Sharing and Reusing Architectural Knowledge.
Asgari, S., Hochstein, L., Basili, V., Zelkowitz, M., Hollingsworth, J., Carver, J., et al. (2005, May 2005). Generating testable hypotheses from tacit knowledge for high productivity computing. Paper presented at the Proceedings of the second international workshop on Software engineering for high performance computing system applications, St. Louis, Missouri.
Baglioni, M., Furletti, B., & Turini, F. (2005). DrC4.5: Improving C4.5 by means of prior knowledge. Paper presented at the Proceedings of the 2005 ACM symposium on Applied computing Santa Fe, New Mexico
Baillie, M., Azzopardi, L., & Crestani, F. (2006). Towards better measures: evaluation of estimated resource description quality for distributed IR. Paper presented at the Proceedings of the 1st international conference on Scalable information systems, Hong Kong.
Banerjee, S. (2008). Improving text classification accuracy using topic modeling over an additional corpus Paper presented at the Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval, Singapore, Singapore.
Bilandzic, M., Foth, M., & Luca, A. D. (2008). CityFlocks: designing social navigation for urban mobile information systems. Paper presented at the Proceedings of the 7th ACM conference on Designing interactive systems Cape Town, South Africa
Bolelli, L., Ertekin, S., Zhou, D., & Giles, C. L. (2009). Finding topic trends in digital libraries. Paper presented at the Proceedings of the 9th ACM/IEEE-CS joint conference on Digital libraries, Austin, TX, USA.
Bondarenko, O., & Janssen, R. (2005). Documents at Hand: Learning from Paper to Improve Digital Technologies. Paper presented at the Proceedings of the SIGCHI conference on Human factors in computing systems, Portland, Oregon, USA.
Borbinha, J., Gil, J., Pedrosa, G., & Penas, J. (2006). The processing of digitized works. Paper presented at the Proceedings of the 6th ACM/IEEE-CS joint conference on Digital libraries, Chapel Hill, NC, USA.
Bortenschlager, M., Reich, S., & Kotsis, G. (2007). An Architectural Approach to Apply the Supervisor/Worker Collaboration Pattern to Nomadic Workspaces. Paper presented at the Proceedings of the 16th IEEE International Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprises
Bossen, C., & Dalsgaard, P. (2005). Conceptualization and appropriation: the evolving use of a collaborative knowledge management system. Paper presented at the Critical Computing: Proceedings of the 4th decennial conference on Critical computing: between sense and sensibility Aarhus, Denmark.
Brinkman, W.-P., & Love, S. (2006). Developing an instrument to assess the impact of attitude and social norms on user selection of an interface design: a repertory grid approach. Paper presented at the Proceedings of the 13th Eurpoean conference on Cognitive ergonomics: trust and control in complex socio-technical systems, Zurich, Switzerland.
Cabitza, F., & Simone, C. (2009). Active artifacts as bridges between context and community knowledge sources. Paper presented at the Proceedings of the fourth international conference on Communities and technologies University Park, PA, USA
Callan, J., Kantor, P., & Grossman, D. (2002). Information retrieval and OCR: from converting content to grasping meaning. ACM SIGIR Forum, 36(2), 58-61.
Canfora, G., & Cerulo, L. (2006). Supporting change request assignment in open source development. Paper presented at the Proceedings of the 2006 ACM symposium on Applied computing, Dijon, France.
Cao, T. M., & Compton, P. (2005). A simulation framework for knowledge acquisition evaluation. Paper presented at the Proceedings of the Twenty-eighth Australasian conference on Computer Science - Volume 38, Newcastle, Australia.
Carenini, G., Ng, R. T., & Zwart, E. (2005, 2005). Extracting knowledge from evaluative text. Paper presented at the Proceedings of the 3rd international conference on Knowledge capture, Banff, Alberta, Canada.
Chklovski, T. (2005). Collecting paraphrase corpora from volunteer contributors. Paper presented at the Proceedings of the 3rd international conference on Knowledge capture, Banff, Alberta, Canada.
Clayton, M. J. (1997). Delphi: A Technique to Harness Expert Opinion for Critical Decision-Making Task in Education. Educational Psychology, 17, 373–386.
Codocedo, V., & Astudillo, H. (2008). No mining, no meaning: relating documents across repositories with ontology-driven information extraction. Paper presented at the Proceeding of the eighth ACM symposium on Document engineering, Sao Paulo, Brazil.
Costa, R. A., Oliveira, R. Y. S., Silva, E. M., & Meira, S. R. L. (2008). A.M.I.G.O.S: knowledge management and social networks. Paper presented at the Proceedings of the 26th annual ACM international conference on Design of communication Lisbon, Portugal
Cruden, G. (2006). Pipeline Integrity Management Is A Matter Of Aligning Knowledge With Strategy. [Feature Article]. Pipeline & Gas Journal, 233(12), 43-45.
Delen, D., & Al-Hawamdeh, S. (2009). A holistic framework for knowledge discovery and management. Communications of the ACM, 52(6), 141-145.
Dey, L., & Haque, S. K. M. (2008). Opinion mining from noisy text data. Paper presented at the Proceedings of the second workshop on Analytics for noisy unstructured text data, Singapore.
Döring, T., & Beckhaus, S. (2007). The card box at hand: exploring the potentials of a paper-based tangible interface for education and research in art history. Paper presented at the Proceedings of the 1st international conference on Tangible and embedded interaction Baton Rouge, Louisiana
Fadel, K. J., Brown, S. A., & Tanniru, M. (2008). A theoretical framework for knowledge transfer in process redesign. ACM SIGMIS Database 39(3), 21-40.
Feng, S., & Manmatha, R. (2006). A hierarchical, HMM-based automatic evaluation of OCR accuracy for a digital library of books. Paper presented at the Proceedings of the 6th ACM/IEEE-CS joint conference on Digital libraries Chapel Hill, NC, USA
Fidel, R., Scholl, H., Liu, S., & Unsworth, K. (2007). Mobile government fieldwork: a preliminary study of technological, organizational, and social challenges. Paper presented at the Proceedings of the 8th annual international conference on Digital government research: bridging disciplines & domains Philadelphia, Pennsylvania
Firpo, D., Kasemvilas, S., Ractham, P., & Zhang, X. (2009). Implementation of an online intellectual community in a graduate educational setting. Paper presented at the Proceedings of the special interest group on management information system's 47th annual conference on Computer personnel research Limerick, Ireland
Forman, G., Eshghi, K., & Chiocchetti, S. (2005). Finding similar files in large document repositories. Paper presented at the Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining, Chicago, Illinois, USA.
Forman, G., & Kirshenbaum, E. (2008). Extremely fast text feature extraction for classification and indexing. Paper presented at the Proceeding of the 17th ACM conference on Information and knowledge management, Napa Valley, California, USA.
Fowles, J. (1978). Handbook of futures research. Westport: Greenwood Publishing Group.
Francesconi, E., & Peruginelli, G. (2007). Searching and retrieving legal literature through automated semantic indexing. Paper presented at the Proceedings of the 11th international conference on Artificial intelligence and law, Stanford, CA, USA.
Fu, Y., Xiang, R., Liu, Y., Zhang, M., & Ma, S. (2007). CDD-based formal model for expert finding. Paper presented at the Proceedings of the sixteenth ACM conference on Conference on information and knowledge management, Lisbon, Portugal.
Fujii, Y., Ebisawa, R., Togashi, Y., Yamada, T., Honda, Y., & Susaki, S. (2008). Third-party approach to controlling digital copiers. Paper presented at the Proceedings of the 10th International Conference on Information Integration and Web-based Applications & Services Linz, Austria
Giannoukos, I., Lykourentzou, I., Mpardis, G., Nikolopoulos, V., Loumos, V., & Kayafas, E. (2008). Collaborative e-learning environments enhanced by wiki technologies. Paper presented at the Proceedings of the 1st international conference on PErvasive Technologies Related to Assistive Environments.
Goldman, K., Gross, P., Heeren, C., Herman, G., Kaczmarczyk, L., Loui, M. C., et al. (2008). Identifying important and difficult concepts in introductory computing courses using a delphi process. Paper presented at the Proceedings of the 39th SIGCSE technical symposium on Computer science education, Portland, OR, USA.
Govindaraju, V. (2005). Emergency medicine, disease surveillance, and informatics. Paper presented at the Proceedings of the 2005 national conference on Digital government research, Atlanta, Georgia.
Govindaraju, V., & Cao, H. (2007, May 2007). Indexing and retrieval of handwritten medical forms. Paper presented at the Proceedings of the 8th annual international conference on Digital government research: bridging disciplines & domains, Philadelphia, Pennsylvania.
Govindaraju, V., Cao, H., & Bhardwaj, A. (2009). Handwritten document retrieval strategies. Paper presented at the Proceedings of The Third Workshop on Analytics for Noisy Unstructured Text Data Barcelona, Spain
Griesemer, R. (2008). Parallelism by design: data analysis with sawzall. Paper presented at the Proceedings of the sixth annual IEEE/ACM international symposium on Code generation and optimization, Boston, MA, USA.
Hafida, B. (2008). Designing a Virtual Organizational Memory- A Case Study. Paper presented at the International Workshop on Advanced Information Systems for Enterprises.
Hasan, H., & Pfaff, C. C. (2006). The Wiki: an environment to revolutionise employees' interaction with corporate knowledge. Paper presented at the Proceedings of the 20th conference of the computer-human interaction special interest group (CHISIG) of Australia on Computer-human interaction: design: activities, artefacts and environments, Sydney, Australia.
Howe, N. R., Rath, T. M., & Manmatha, R. (2005). Boosted decision trees for word recognition in handwritten document retrieval. Paper presented at the Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval, Salvador, Brazil.
Huh, J., Jones, L., Erickson, T., Kellogg, W. A., Bellamy, R. K. E., & Thomas, J. C. (2007). BlogCentral: the role of internal blogs at work. Paper presented at the CHI '07 extended abstracts on Human factors in computing systems San Jose, CA, USA
Jervis, M., & Masoodian, M. (2009). Digital management and retrieval of physical documents. Paper presented at the Proceedings of the 3rd International Conference on Tangible and Embedded Interaction Cambridge, United Kingdom
John, D. L., Ian, W. H., & Andres, C. R. (2001). Capturing analytic thought. Paper presented at the Proceedings of the 1st international conference on Knowledge capture, Victoria, British Columbia, Canada.
Kaiser, E. C. (2005, January 2005). Multimodal new vocabulary recognition through speech and handwriting in a whiteboard scheduling application. Paper presented at the Proceedings of the 10th international conference on Intelligent user interfaces, San Diego, California, USA.
Kienzle, W., & Chellapilla, K. (2006). Personalized handwriting recognition via biased regularization. Paper presented at the Proceedings of the 23rd international conference on Machine learning, Pittsburgh, Pennsylvania.
Konishi, K., Furukawa, N., & Ikeda, H. (2007). Data model and architecture of a paper-digital document management system. Paper presented at the Proceedings of the 2007 ACM symposium on Document engineering Winnipeg, Manitoba, Canada
Liao, C., Guimbretière, F., Hinckley, K., & Hollan, J. (2008). Papiercraft: A gesture-based command system for interactive paper. ACM Transactions on Computer-Human Interaction, 14(4), 1-27.
Linstone, H. A., & Turoff, M. (2002). The Delphi Method: Techniques and Applications.
Liu, S., & Fidel, R. (2007). Managing aging workforce: filling the gap between what we know and what is in the system. Paper presented at the ACM International Conference Proceeding Series, Macao, China.
Lund, W. B., & Ringger, E. K. (2009). Improving optical character recognition through efficient multiple system alignment. Paper presented at the Proceedings of the 9th ACM/IEEE-CS joint conference on Digital libraries Austin, TX, USA
Magdy, W., & Darwish, K. (2008). Book search: indexing the valuable parts. Paper presented at the Proceeding of the 2008 ACM workshop on Research advances in large digital book repositories Napa Valley, California, USA
Makolm, J., Wei, S., & Reisinger, D. (2007). Proactive knowledge management: the DYONIPOS research and use-case project. Paper presented at the Proceedings of the 1st international conference on Theory and practice of electronic governance, Macao, China.
Mane, V., & Ragha, L. (2009). Handwritten character recognition using elastic matching and PCA. Paper presented at the Proceedings of the International Conference on Advances in Computing, Communication and Control Mumbai, India
Marks, P., Polak, P., McCoy, S., & Galletta, D. (2008). Sharing knowledge. Communications of the ACM 51(2), 60-65.
Mikeal, A., Creel, J., Maslov, A., Phillips, S., Leggett, J., & McFarland, M. (2009). Large-scale ETD repositories: a case study of a digital library application Paper presented at the Proceedings of the 9th ACM/IEEE-CS joint conference on Digital libraries, Austin, TX, USA
Mooney, R. J., & Bunescu, R. (2005). Mining knowledge from text using information extraction. ACM SIGKDD Explorations Newsletter 7(1), 3-10.
Mueller, F. F., Kethers, S., Alem, L., & Wilkinson, R. (2006). From the certainty of information transfer to the ambiguity of intuition. Paper presented at the Proceedings of the 20th conference of the computer-human interaction special interest group (CHISIG) of Australia on Computer-human interaction: design: activities, artefacts and environments, Sydney, Australia.
Muller, M. J. (2007). Collaborative activity management: organizing documents for collective action. Paper presented at the Proceedings of the 25th annual ACM international conference on Design of communication, El Paso, Texas, USA.
Mwebesa, T. M. T., Baryamureeba, V., & Williams, D. (2007). Collaborative framework for supporting indigenous knowledge management. Paper presented at the Proceedings of the ACM first Ph.D. workshop in CIKM Lisbon, Portugal
Neves, L. A. P., Carvalho, J. M. d., Facon, J., & Bortolozzi, F. (2007). A table-form extraction with artefact removal. Paper presented at the Proceedings of the 2007 ACM symposium on Applied computing Seoul, Korea.
Nikolov, N., & Stoehr, P. (2008). Harvesting needed to maintain scientific literature online. Paper presented at the Proceedings of the 8th ACM/IEEE-CS joint conference on Digital libraries, Pittsburgh PA, PA, USA.
Nitko, A. (1996). Educational assessment of standards (2nd ed.). Englewood Cliffs NJ: Prentice Hall/Merrill Education.
Nomura, S., Hutchins, E., & Holder, B. E. (2006). The uses of paper in commercial airline flight operations. Paper presented at the Proceedings of the 2006 20th anniversary conference on Computer supported cooperative work Banff, Alberta, Canada.
Norrie, M. C., Palinginis, A., & Signer, B. (2005). Content publishing framework for interactive paper documents. Paper presented at the Proceedings of the 2005 ACM symposium on Document engineering, Bristol, United Kingdom.
Onkov, K. Z. (2009). Effect of OCR-errors on the transformation of semi-structured text data into relational database. Paper presented at the Proceedings of The Third Workshop on Analytics for Noisy Unstructured Text Data, Barcelona, Spain.
Otsuki, A., & Okada, K. (2009). The study of the knowledge optimization tool. Paper presented at the Proceedings of the first ACM/SIGEVO Summit on Genetic and Evolutionary Computation Shanghai, China
Ott, R. L. (1992). An Introduction to Statistical Methods and Data Analysis (Fourth ed.). Belmont: Duxbury Press.
Pasca, M. (2007). Lightweight web-based fact repositories for textual question answering. Paper presented at the Proceedings of the sixteenth ACM conference on Conference on information and knowledge management, Lisbon, Portugal.
Preston, J. A., Hu, X., & Prasad, S. K. (2007). Simulation-based architectural design and implementation of a real-time collaborative editing system. Paper presented at the Proceedings of the 2007 spring simulation multiconference, Norfolk, Virginia
Rader, E. (2007). Just email it to me!: why things get lost in shared file repositories. Paper presented at the Conference on Supporting Group Work, Sanibel Island, Florida.
Raitman, R., Augar, N., & Zhou, W. (2005). Employing Wikis for Online Collaboration in the E-Learning Environment: Case Study. Third International Conference on Information Technology and Applications, 2, 4.
Rath, T. M., Manmatha, R., & Lavrenko, V. (2004). A search engine for historical manuscript images. Paper presented at the Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval Sheffield, United Kingdom.
Rodrigues, M. A. F., & Chaves, R. R. C. (2007). Performance and user based analysis of a collaborative virtual environment system. Paper presented at the Proceedings of the 5th international conference on Computer graphics and interactive techniques in Australia and Southeast Asia Perth, Australia
Sakai, S., Gotou, M., Murakami, Y., Morimoto, S., Morita, D., Tanaka, M., et al. (2009). Language grid playground: light weight building blocks for intercultural collaboration. Paper presented at the Proceeding of the 2009 international workshop on Intercultural collaboration
Sammon, M. J., Brotman, L. S., Peebles, E., & Seligmann, D. D. (2006). MACCS: enabling communications for mobile workers within healthcare environments. Paper presented at the Proceedings of the 8th conference on Human-computer interaction with mobile devices and services
Scholl, H., Fidel, R., & Mai, J.-E. (2006). The fully mobile city government project (MCity). Paper presented at the Proceedings of the 2006 international conference on Digital government research
Scholl, H., Liu, S., Fidel, R., & Unsworth, K. (2007). Choices and challenges in e-government field force automation projects: insights from case studies. Paper presented at the Proceedings of the 1st international conference on Theory and practice of electronic governance, Macao, China.
Scholl, H., Mai, J.-E., & Fidel, R. (2006). Interdisciplinary analysis of digital government work. Paper presented at the Proceedings of the 2006 international conference on Digital government research
Schreiber, G., Wielinga, B., & Breuker, J. (1993). KADS: a principled approach to knowledge-based system development in Knowledge-based systems. Academic Press.
Shen, W.-C. (2008). Does knowledge work pay?: an archival analysis of knowledge management activities. Paper presented at the Proceedings of the 2008 ACM SIGMIS CPR conference on Computer personnel doctoral consortium and research, Charlottesville, VA, USA
Shilman, M., Tan, D. S., & Simard, P. (2006). CueTIP: a mixed-initiative interface for correcting handwriting errors. Paper presented at the Proceedings of the 19th annual ACM symposium on User interface software and technology Montreux, Switzerland.
Song, H., Grossman, T., Fitzmaurice, G., Guimbretiere, F., Khan, A., Attar, R., et al. (2009). PenLight: combining a mobile projector and a digital pen for dynamic visual overlay. Paper presented at the Proceedings of the 27th international conference on Human factors in computing systems Boston, MA, USA
Song, S., Nerur, S., & Teng, J. T. C. (2008). Understanding the influence of network positions and knowledge processing styles. Communications of the ACM 51(10), 123-126.
Stamatopoulos, N., Louloudis, G., & Gatos, B. (2009). A comprehensive evaluation methodology for noisy historical document recognition techniques. Paper presented at the Proceedings of The Third Workshop on Analytics for Noisy Unstructured Text Data Barcelona, Spain
Steimle, J. (2009). Designing pen-and-paper user interfaces for interaction with documents. Paper presented at the Proceedings of the 3rd International Conference on Tangible and Embedded Interaction Cambridge, United Kingdom
Su, N. M., Wilensky, H., Redmiles, D., & Mark, G. (2007). The gospel of knowledge management in and out of a professional community. Paper presented at the Proceedings of the 2007 international ACM conference on Supporting group work, Sanibel Island, Florida, USA.
Terry, M., Cheung, J., Lee, J., Park, T., & Williams, N. (2007). Jump: a system for interactive, tangible queries of paper. Paper presented at the Proceedings of Graphics Interface 2007 Montreal, Canada
Thomson, P., Saunders, J., & Foyster, J. (2001). Improving the validity of competency-based assessment. Adelaide: NCVER.
van der Merwe, A., & Kroeze, J. H. (2008). Development and implementation of an institutional repository within a science, engineering and technology (SET) environment. Paper presented at the Proceedings of the 2008 annual research conference of the South African Institute of Computer Scientists and Information Technologists on IT research in developing countries: riding the wave of technology, Wilderness, South Africa.
Wang, X., Li, J., Ao, X., Wang, G., & Dai, G. (2006). Multimodal error correction for continuous handwriting recognition in pen-based user interfaces. Paper presented at the Proceedings of the 11th international conference on Intelligent user interfaces, Sydney, Australia.
Weibel, N., Ispas, A., Signer, B., & Norrie, M. C. (2008). Paperproof: a paper-digital proof-editing system. Paper presented at the CHI '08 extended abstracts on Human factors in computing systems Florence, Italy
White, K. F., & Lutters, W. G. (2007). Structuring cross-organizational knowledge sharing. Paper presented at the Proceedings of the 2007 international ACM conference on Supporting group work Sanibel Island, Florida, USA
Wong, S. C., Crowder, R. M., Wills, G. B., & Shadbolt, N. R. (2007). Lesson learnt from a large-scale industrial semantic web application. Paper presented at the Proceedings of the eighteenth conference on Hypertext and hypermedia, Manchester, UK.
Wu, H., Zubair, M., & Maly, K. (2006). Harvesting social knowledge from folksonomies. Paper presented at the Proceedings of the seventeenth conference on Hypertext and hypermedia, Odense, Denmark.
Yeh, T., & Katz, B. (2009). Searching documentation using text, OCR, and image. Paper presented at the Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval Boston, MA, USA
Yesilada, Y., Brajnik, G., & Harper, S. (2009). How much does expertise matter?: a barrier walkthrough study with experts and non-experts. Paper presented at the Proceeding of the eleventh international ACM SIGACCESS conference on Computers and accessibility Pittsburgh, Pennsylvania, USA
Yordanova, K. (2007). Integration of knowledge management and e-learning: common features. Paper presented at the Proceedings of the 2007 international conference on Computer systems and technologies Bulgaria
Yoshinori, H., Toshihiro, T., Yukitaka, K., & Shogo, N. (2007). Interactive knowledge externalization and combination for SECI model. Paper presented at the Proceedings of the 4th international conference on Knowledge capture, Whistler, BC, Canada.
You, D., Shi, Z., Govindaraju, V., & Blatt, A. (2009). Line removal and handwritten word recognition of police accident report forms. Paper presented at the Proceedings of the 10th Annual International Conference on Digital Government Research: Social Networks: Making Connections between Citizens, Data and Government.